Vous envisagez de construire un Data Warehouse dans le Cloud pour extraire, stocker et analyser les données issues de vos différents systèmes sources ? Nous allons vous proposer l’une des solutions à envisager très sérieusement : Snowflake Data Warehouse Cloud, solution SaaS simple d’utilisation, facile à gérer, puissante et relativement abordable.
Découvrez sans plus attendre l’essentiel à connaître sur Snowflake Data Warehouse Cloud, ses caractéristiques, sont fonctionnement tripartite, les offres et tarifs, les avantages et limites, les alternatives…
Sommaire :
- En quoi consiste la solution Data Warehouse Cloud proposée par Snowflake ?
- Snowflake Cloud Data Warehouse – Une architecture tripartite
- Performance de Snowflake DWH Cloud
- Data Warehouse Cloud Snowflake & ETL
- La mise à l’échelle dans le Data Warehouse Cloud Snowflake (Scaling up & Scaling down)
- Modèle(s) de tarification de Snowflake Data Warehouse Cloud
- La gestion de la sécurité et de la maintenance dans Snowflake Data Warehouse Cloud
- Snowflake DWH Cloud : Avantages & Limites
- Les 3 principales alternatives à Snowflake Data Warehouse Cloud
En quoi consiste la solution Data Warehouse Cloud proposée par Snowflake ?
Snowflake propose une solution Data Warehouse Cloud, distribuée en mode SaaS. Comme tout produit distribué en mode SaaS, c’est l’éditeur du produit (les équipes de Snowflake) qui s’occupent de la maintenance de la solution. Nous y reviendrons tout au long de l’article, mais disons d’emblée que l’un des gros avantages de Snowflake est qu’elle décharge vos équipes des tâches d’installation, de configuration et de maintenance. Pas de serveurs à installer. Pas de logiciels à paramétrer. Snowflake s’occupe de tout. La solution proposée par Snowflake est « sur l’étagère ».
Snowflake Data Warehouse Cloud permet de créer facilement un Data Warehouse à partir des données issues de votre système d’information. Snowflake peut être hébergé sur les différentes bases cloud / data lakes du marché : Amazon Web Services (depuis 2014), Microsoft Azure (depuis 2018) et la Google Cloud Platform (depuis 2019). Vous pouvez choisir le type de fournisseurs cloud que vous souhaitez utiliser pour votre instance Snowflake. C’est particulièrement pratique si vous êtes une entreprise qui utilise plusieurs fournisseurs cloud. Le système de requêtes de Snowflake utilise le protocole standard ANSI SQL et gère aussi bien les données structurées que les données semi-structurées de type JSON ou XML.
L’alimentation en données entre les sources de données et Snowflake s’effectue généralement via une solution ETL Cloud, type Stitch data ou Fivetran. Sous forme de batchs ou en quasi-temps réel, le script ETL charge les données (brutes ou non) à partir de vos sources de données et les intègre dans la table SQL de votre Data Warehouse Cloud.
Vous me direz, Snowflake n’est pas le seul acteur du marché à proposer une solution de Data Warehouse Cloud. C’est l’architecture de Snowflake et ses capacités en matière de partage des données en temps réel qui font de Snowflake une solution très puissante. Les fonctions de stockage et les fonctions de calcul sont séparées, les calculs étant réalisés sur des instances virtuelles (virtual datawarehouses). Par exemple, si vous avez un énorme besoin de stockage mais des besoins moins importants en termes de requêtes SQL, ou inversement, vous n’avez pas à payer un forfait intégré qui impose de payer les deux.

Snowflake Cloud Data Warehouse – Une architecture tripartite
Snowflake propose une architecture IT composée de trois niveaux / trois couches :

Les 3 composantes clés de cette architecture, qui est entièrement construites dans le Cloud, sont, de bas en haut :
#1 Le stockage des données
Snowflake est un entrepôt de données qui stocke les données en provenance de vos différents systèmes / sources. Les données qui arrivent dans le Data Warehouse Cloud font l’objet en amont d’un travail de préparation, de formatage, de compression, de déduplication. Les données sont travaillées pour s’intégrer dans le format colonne du DWH…C’est la base même du process ETL qui gouverne le fonctionne des Data Warehouse au niveau de l’ingestion des données : Extract – Transform – Load. On transforme la donnée avant de la charger dans l’entrepôt. Nous avons produit plusieurs articles décrivant en détail cette mécanique. Sachez que Snowflake gère automatiquement tous les aspects relatifs à la manière dont les données sont stockées dans la base : organisation, taille de fichiers, structure, compression, métadonnées, statistiques…Cette couche de stockage fonctionne indépendamment des ressources de calcul. Une précision, qui est la conséquence de ce qui précède : les données stockées dans cette couche ne sont pas directement accessibles aux utilisateurs – ces derniers y accèdent via des requêtes SQL.
#2 Le traitement des requêtes
Le layer de calcul est celui où vous effectuez les requêtes SQL. Dans Snowflake, cette couche est constitué d’entrepôts virtuels sur lesquels sont exécutées les actions de data processing à partir de vos requêtes SQL. Chaque entrepôt virtuel (des clusters de calcul en EC2) a son propre environnement MPP dédié et est constitué d’un nombre de noeuds de calcul personnalisable. Chaque entrepôt virtuel (ou cluster) peut accéder à l’ensemble des données de la composante de stockage présentée plus haut. En clair, le data processing ne s’effectue pas directement sur la base de données du Data Warehouse mais sur les différentes entrepôts virtuels connectés reliés à lui. Cela permet de travailler indépendamment sur les couches Storage et Compute.
Toutes les requêtes SQL sont réalisées sur un cluster précis qui est constitué d’un nombre de noeuds de calcul personnalisables et exécutées dans un environnement MPP dédié. Cela permet d’avoir des entrepôts de données (virtuels) qui ne se disputent pas la donnée stockée dans la base. Vous pouvez faire tourner plusieurs workloads en même temps. Cela rend possible un scaling automatique et sans interruption, ce qui signifie que pendant l’exécution des requêtes, les ressources informatiques peuvent évoluer sans qu’il soit nécessaire de redistribuer ou de rééquilibrer les données dans la couche de stockage. Vous pouvez à tout moment créer et supprimer des entrepôts virtuels si vous n’en avez plus besoin, ce qui vous permet de réduire vos coûts de data processing de manière flexible, sans avoir à toucher au socle de la base de données.
En résumé, cette architecture vous permet de créer autant de Data Marts que vous le souhaitez de manière simple, flexible et peu coûteuse. Avec Snowflake Data Warehouse Cloud, on est sur une solution intermédiaire entre les Data Warehouses traditionnels à disque partagé (> La couche Data Storage) et les architectures « shared-nothing » (les requêtes SQL sont traités à partir de virtual data warehouses). On a le meilleure des mondes : la simplicité du shared-disk, et la souplesse/performance du shared-nothing.
#3 Les services cloud
La couche de services cloud, dernier étage de la fusée, utilisent l’ANSI SQL et coordonnent l’ensemble du système. Ce sont ces services qui vous épargnent d’avoir à gérer et régler manuellement votre Data Warehouse Cloud. Voici quelques’uns des services proposés par Snowflake : Authentification, gestion de l’infractructure, gestion des métadonnées, analyse et optimisation des requêtes SQL, contrôle des accès, cryptage des données…Comme nous le disions plus haut, c’est l’un des points forts de la solution proposée par Snowflake. L’éditeur gère tout, la compression des données, leur organisation, leur structure, les métadonnées…Solution Cloud, Snowflake est aussi une solution SaaS.

Comme nous le disions en passant tout à l’heure, l’un des avantages de la solution Snowflake Data Warehouse Cloud, c’est que ces trois couches peuvent évoluer de manière indépendante. Le contenant (la base de données) et le contenu (ce que vous faites à l’intérieur de cette base) sont séparés. Les trois couches sont distinctes toute en étant parfaitement intégrées entre elles – nous sommes dans le même écosystème. Cette indépendance permet un meilleur contrôle des utilisateurs sur ce qu’ils utilisent et une meilleure maîtrise des coûts du Data Warehouse Cloud. C’est l’une des grandes forces du modèle économique de Snowflake. Insistons sur le fait que Snowflake est la seule solution à proposer cette architecture Data Warehouse 100% Cloud.
Découvrez notre guide complet sur le Reverse ETL, la brique Data pour réellement actionner les données de votre Data Warehouse.
Le coût très faible du stockage vous permet de conserver l’ensemble de vos données dans le Data Warehouse et de les utiliser dans plusieurs entrepôts virtuels sans que cela fasse augmenter démesurément la facture. Le stockage cloud est bel et bien devenu une commodité, et Snowflake le démontre parfaitement. Dans ce contexte, la redondance des données qu’engendre la multiplication des clusters n’a pas quasiment pas d’impact sur les coûts du système. En définitive, la couche Data Storage fait presque office de Data Lake. Elle permet d’intégrer et de conserver le maximum de données, en prévision de cas d’usage futurs (déjà imaginés ou à imaginer). On est à des années lumières des coûts souvent faramineux de stockage qu’impliquaient les Data Warehouses On-Premise montés sur des serveurs locaux.
Performance de Snowflake DWH Cloud
La solution Data Warehouse de Snowflake a été conçue dans un souci de simplicité et d’efficacité maximale grâce à l’exécution parallèle des charges de travail via l’architecture MPP. L’idée d’augmenter la performance des requêtes est passée des options traditionnelles d’optimisation manuelle de la performance comme l’indexation, le tri, etc. au suivi de certaines meilleures pratiques généralement applicables. Ce qui inclut :
#1 La séparation des charges de travail
Étant donné qu’il est très facile de créer plusieurs entrepôts de données virtuels avec le nombre souhaité de nœuds de calcul, il est courant de diviser les charges de travail en clusters séparés en fonction des unités commerciales (ventes, marketing, etc.) ou du type d’opération (analyse de données, chargements ETL/BI, etc.). Il est également intéressant de noter que les entrepôts de données virtuels peuvent être configurés pour se suspendre automatiquement lorsqu’ils deviennent inactifs (par défaut, au bout de 10 minutes) ou, en d’autres termes, lorsqu’aucune requête n’est exécutée. Cette fonction permet aux clients d’éviter d’accumuler des coûts importants en faisant fonctionner plusieurs entrepôts de données virtuels en parallèle.
#2 Résultats persistants ou en cache
Les résultats des requêtes sont stockés ou mis en cache pendant un certain temps (par défaut, 24 heures). Cette fonction est utilisée lorsqu’une requête est essentiellement réexécutée pour obtenir le même résultat. La mise en cache se fait à deux niveaux : le cache local et le cache des résultats. Le cache local fournit les résultats stockés pour les utilisateurs du même entrepôt de données virtuel, tandis que le cache des résultats contient les résultats qui peuvent être récupérés par les utilisateurs indépendamment de l’entrepôt de données virtuel auquel ils appartiennent
Data Warehouse Cloud Snowflake & ETL
L’ETL est le process qui consiste à extraire les données (à partir des sources de données), à la transformer dans un certain format (généralement, le format qui correspond à la table cible) avant de la charger pour finir dans la table/base de données cible : le Data Warehouse.
La source et la cible sont souvent deux entités ou systèmes de base de données différents. Parmi les exemples, citons le chargement d’un fichier plat dans une table Oracle, l’exportation de données CRM dans une table Amazon Redshift, la migration de données d’une base de données Postgres vers un entrepôt de données Snowflake, etc.
Snowflake a été conçu pour se connecter à une multitude d’intégrateurs de données en utilisant une connexion JDBC ou ODBC.
En termes de chargement des données, Snowflake propose deux méthodes :
- Bulk Loading. Il s’agit essentiellement du chargement par lots de fichiers de données à l’aide de la commande COPY. La commande COPY permet aux utilisateurs de copier des fichiers de données du stockage cloud vers les tables Snowflake. Cette étape implique l’écriture d’un code qui est généralement programmé pour s’exécuter à intervalles réguliers.
- Continuous Loading. Dans ce cas, de plus petites quantités de données sont extraites de l’environnement de préparation (dès qu’elles sont disponibles) et chargées par incréments rapides dans une table Snowflake cible. La fonctionnalité appelée Snowpipe rend cela possible. Le continuous loading permet de se rapprocher du streaming de données en temps réel.
Snowflake offre un tas d’options de transformation pour les données entrantes avant le chargement. Ceci est réalisé par la commande COPY. Certaines de ces options incluent la réorganisation des colonnes, l’ommision de colonnes, les conversions à l’aide d’une instruction SELECT.
La mise à l’échelle dans le Data Warehouse Cloud Snowflake (Scaling up & Scaling down)
Nous avons abordé jusqu’à présent trop brièvement la question des entrepôts de données virtuels, des clusters, des nœuds, etc. Nous allons maintenant nous plonger dans ces domaines afin de mieux comprendre comment les adapter pour permettre une mise à l’échelle plus efficace.
Snowflake propose deux méthodes pour mettre le Data Warehouse Cloud à l’échelle : le scaling up et le scaling out. Ces deux workflows de mise à l’échelle sont toutes deux dites « horizontales » (vs le scaling up & down).
#1 Le scaling up
Le scaling up signifie le redimensionnement d’un entrepôt de données virtuel en termes de nœuds. Un utilisateur de Snowflake Data Warehouse peut facilement modifier le nombre de nœuds affectés à un entrepôt de données virtuel. Il peut le faire même lorsque l’entrepôt de données est en cours de fonctionnement, mais seules les requêtes nouvellement soumises ou celles qui sont déjà en file d’attente seront affectées par les changements. Outre la fonction de suspension automatique décrite précédemment, il est possible de définir le nombre minimum et maximum de nœuds par entrepôt.
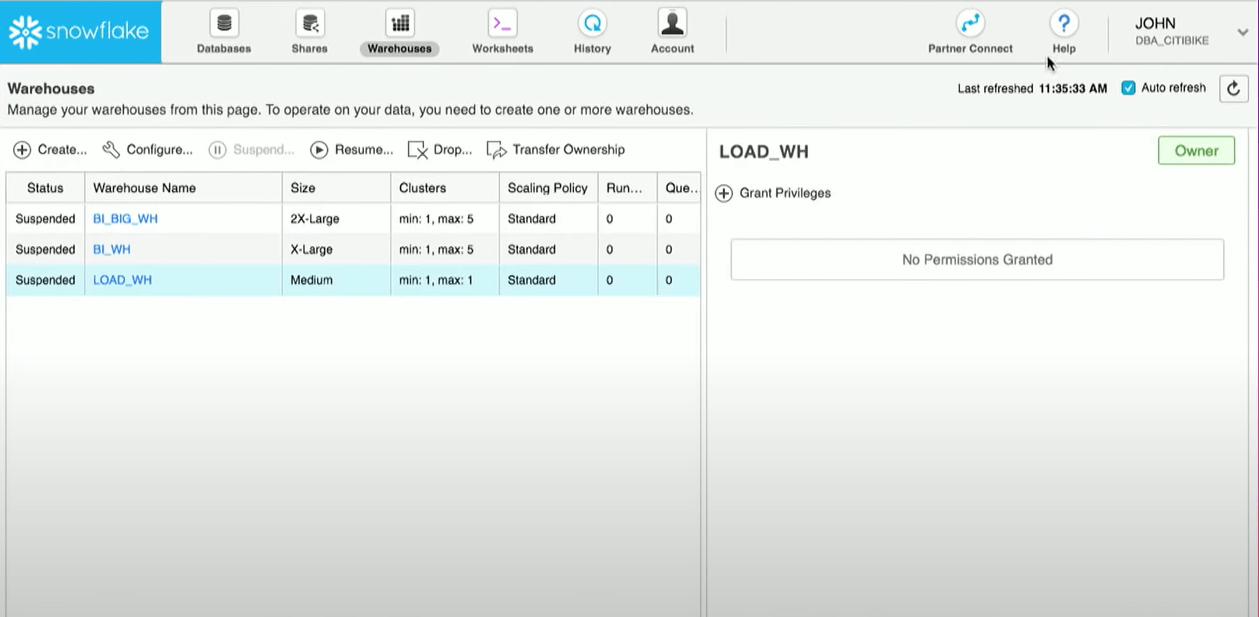
Après avoir défini le nombre maximum et minimum de nœuds, vous pouvez laisser Snowflake décider quand augmenter ou diminuer le nombre de nœuds en fonction de l’activité de l’entrepôt. Il s’agit d’une manière efficace de mettre en place votre cluster. L’approche scaling up est particulièrement indiquée dans les cas suivants :
- Pour améliorer les performances des requêtes dans le cas de requêtes plus importantes et plus complexes.
- Lorsque les requêtes soumises utilisent le même cache local.
- L’option de mise à l’échelle scale out n’est pas disponible.
Le scaling out est généralement l’option privilégiée, en particulier avec l’ajout et la disponibilité plus récente des entrepôts multi-clusters, qui seront abordés plus loin.
Découvrez tout ce qu’il faut savoir sur les différences entre un Data Warehouse et un Data Lake.
#2 Le Scaling out
Avant, le Scaling out consistait à ajouter des entrepôts de données virtuels supplémentaires. Toutefois, avec l’arrivée de la récente fonctionnalité d’entrepôt multi-clusters, l’ancienne méthode est devenue plus ou moins obsolète. Comme son nom l’indique, dans ce type de configuration, un entrepôt de données peut avoir plusieurs clusters, chacun ayant un ensemble différent de nœuds. Même si Snowflake propose un mode « maximisé », qui consiste à demander au Data Warehouse de faire fonctionner tous ses clusters sans tenir compte des autres, dans la plupart des cas, il est préférable d’opter pour la mise à l’échelle automatique. Voici un exemple de ce à quoi ressemble la mise à l’échelle automatique.

Comme vous pouvez le constater, vous pouvez définir un grand nombre de paramètres. Les fonctions « Auto-Scale et « Auto-suspend » offrent une certaine flexibilité pour l’exécution des requêtes ainsi que pour la gestion des coûts. Nous verrons dans un instant comment cela fonctionne.
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisModèle(s) de tarification de Snowflake Data Warehouse Cloud
Snowflake a un modèle de tarification relativement simple. Comme nous le disions plus haut, le stockage et le calcul sont facturés indépendamment. Le stockage est facturé pour chaque téraoctet (TB) d’utilisation tandis que le calcul est facturé à la seconde par unité de calcul (ou crédit). Avant d’entrer dans un exemple, il est utile de noter que Snowflake propose deux modèles de tarification plus larges :
- La tarification à l’usage. Vous payez en fonction de votre utilisation (stockage et calcul).
- Les offres pré-payées .Une capacité déterminée de stockage et de calcul peut être achetée à l’avance à un prix réduit.

Les deux offres les plus populaires : Standard & Enterprise
Offre Standard
Le stockage vous coûte environ 23 dollars par To et les coûts de calcul s’élèvent à environ 4 cents par minute et par crédit, facturés pour une durée minimale d’une minute.
Offre Enterprise
Cette offre premium est dotée de fonctions avancées de cryptage et de sécurité, ainsi que de la conformité HIPAA. Résultat : le coût du stockage reste à peu près le même que dans l’offre Standard, en revanche le coût du calcul passe à environ 6,6 cents par minute et par crédit.
Les frais de calcul ci-dessus ne s’appliquent qu’aux Data Warehouses « actifs » et tout temps de session inactif n’est pas facturé. C’est pourquoi il est vraiment intéressant de configurer des fonctions telles que l’auto-suspension et la mise à l’échelle automatique pour optimiser vos coûts.
La gestion de la sécurité et de la maintenance dans Snowflake Data Warehouse Cloud
La sécurité des données est traitée très sérieusement à tous les niveaux de l’écosystème Snowflake. Quelle que soit la version, toutes les données sont cryptées à l’aide d’AES 256, et les versions d’entreprise haut de gamme sont dotées de fonctions de sécurité supplémentaires, comme le recodage périodique des clés, etc.
Comme Snowflake est déployé sur un serveur cloud comme AWS ou MS Azure, les fichiers de données en transit (prêts à être chargés/déchargés) dans ces serveurs bénéficient du même niveau de sécurité que les fichiers en transit pour Amazon Redshift ou Azure SQL Data Warehouse. Pendant leur transit, les données sont fortement protégées à l’aide de protocoles sécurisés.
En ce qui concerne la maintenance, Snowflake étant une solution Data Warehouse Cloud proposée en mode SaaS, les utilisateurs finaux n’ont pratiquement rien à faire pour assurer le bon fonctionnement de l’entrepôt de données au quotidien. Cela aide énormément les clients à se concentrer davantage sur les opérations de données frontales, telles que l’exploration et l’analyse des données, et moins sur les activités de back-end, telles que les performances du serveur et les activités de maintenance.
Snowflake DWH Cloud : Avantages & Limites
Comme toute solution, le Data Warehouse Cloud Snowflake a des avantages (évidents et importants), mais aussi certaines limites. Commençons par les avantages.
Avantages de Snowflake DWH Cloud
Voici les principaux avantages qu’il y a à utiliser Snowflake Data Warehouse Cloud pour gérer votre entrepôt de données :
- Solution gérée et déployée à 100% dans le Cloud, dont la mise en place et le fonctionnement ne demandent qu’un minimum d’efforts.
- Performance et vitesse d’exécution des requêtes. La souplesse du cloud signifie que si vous souhaitez charger des données plus rapidement ou exécuter un volume élevé de requêtes, vous pouvez faire évoluer votre entrepôt virtuel pour tirer parti des ressources de calcul supplémentaires. Ensuite, vous pouvez réduire l’entrepôt virtuel et ne payer que pour le temps utilisé.
- Facile à faire évoluer grâce à de nombreuses options flexibles.
- Possibilité de séparer le stockage et le calcu. Snowflake est quasiment le seul acteur du marché à proposer ce modèle tarifaire.
- Suit le protocole ANSI SQL et prend en charge tous les types de données structurées et semi-structurés comme JSON, Avro, Parquet, XML, ORC, etc. Vous pouvez combiner des données structurées et semi-structurées à des fins d’analyse et les charger dans la base de données cloud sans qu’il soit nécessaire de les convertir ou de les transformer au préalable en un schéma relationnel fixe. Snowflake optimise automatiquement la manière dont les données sont stockées et requêtée.
- Un acteur solide, jouissant d’une belle notoriété et ayant de très belles références clients. Snowflake concurrence les mastodontes que sont Amazon Redshift, BigQuery…
Limites & inconvénients de Snowflake DWH Cloud
Passons maintenant aux inconvénients :
- La dépendance de Snowflake à l’égard d’AWS, Azure ou GCS peut parfois poser problème en cas de panne indépendante (indépendante de la « santé » des opérations de Snowflake) de l’un des serveurs cloud.
- Pas de prise en charge des données non-structurées.
Découvrez notre guide complet sur la modélisation en étoile d’un Data Warehouse.
Les 3 principales alternatives à Snowflake Data Warehouse Cloud
L’évolution vers des solutions d’entreposage de données cloud s’est véritablement accélérée à la fin des années 2000, principalement grâce à Google et Amazon. Depuis, de nombreux fournisseurs de bases de données traditionnels comme Microsoft, Oracle, etc. ainsi que des acteurs plus récents comme Vertica ou Panoply ont pénétré le marché. Les 3 principales alternatives à Snowflake Data Warehouse sont : Amazon Redshift, Google BigQuery et Microsoft Azure SQL.
#1 Amazon Redshift

Amazon Redshift est la solution Data Warehouse Cloud proposée par Amazon, qui est aussi l’un des plus gros fournisseurs de données avec Amazon Web Services, AWS. Amazon Redshift peut travailler avec des données à l’échelle du pétaoctet. La solution prend en charge les données entièrement structurées ainsi que certaines données semi-structurées comme JSON, stockées en format colonne. Cependant, le calcul et le stockage ne sont pas séparés comme dans Snowflake. Généralement, une alternative plus coûteuse que Snowflake mais plus robuste et plus rapide avec des techniques de réglage optimisables comme les vues matérialisées, les clés de tri/distribution, etc.
#2 Google BigQuery

Faisant partie de la suite Google Cloud Services, BigQuery est une solution de Data Warehouse Cloud permettant de stocker des données en colonnes. BigQuery possède d’autres caractéristiques comparables à Amazon Redshift, comme l’architecture MPP. Il peut être facilement intégré à d’autres fournisseurs de données, etc. BigQuery est similaire à Snowflake dans le sens où le stockage et le calcul sont traités séparément. Toutefois, au lieu du modèle de tarification pré-payé (comme dans Snowflake), les services BigQuery sont facturés mensuellement/annuellement à un taux fixe.
#3 Microsoft Azure SQL

Azure gagne progressivement en popularité et est particulièrement connu pour l’exécution de tâches analytiques. Il fait partie de la suite de produits Microsoft, ce qui présente un avantage naturel pour les utilisateurs et les entreprises qui utilisent des produits et des technologies MS comme SQL Server, SSRS, SSIS, T-SQL, etc. Il s’agit également d’une base de données en colonnes, où le stockage et le calcul sont séparés. Le moteur Azure SQL est également connu pour son niveau élevé de concurrence.
A retenir :
- Architecture Tripartite: Snowflake utilise une architecture tripartite pour une gestion des données plus efficace.
- Mise à l’échelle: Snowflake offre des options de mise à l’échelle flexibles, à la fois verticales et horizontales.
- Tarification Flexible: Snowflake sépare les coûts de stockage et de calcul, offrant une tarification plus flexible.
Conclusion
Comme nous avons pu le voir, Snowflake Data Warehouse Cloud est une solution puissante, sécurisée, scalable et de plus en plus populaire. Si vous avez des questions à propos de Snowflake, ou plus largement au sujet de vos problématiques en matière d’architecture Data, n’hésitez pas à nous contacter.
Laisser un commentaire