Un Data Lake est un espace de stockage centralisé qui permet de conserver un grand volume de données, qu’elles soient structurées, semi-structurées ou non-structurées, dans leur format brut, en vue d’une utilisation ultérieure, notamment pour des cas d’usage en Data Science.
Un Data Lake est donc très différent d’un Data Warehouse (qui a des finalités beaucoup plus métiers, marketing notamment). Dans cet article, l’essentiel de ce qu’il faut savoir sur le Data Lake.
Qu’est-ce qu’un Data Lake ?
Définition d’un Data Lake & Principes clés
Commençons par une analogie pour mieux comprendre ce qu’est un Data Lake. Imaginez un grand lac dans lequel se déversent de multiples rivières et ruisseaux. Chacun de ces cours d’eau apporte au lac des éléments différents : de l’eau bien sûr, mais aussi des poissons, des végétaux, des sédiments…
C’est un peu le même principe avec un Data Lake, mais avec des données à la place de l’eau !
Plus concrètement, un Data Lake est un espace de stockage centralisé qui permet de collecter de très grands volumes de données dans leur format d’origine. C’est en quelque sorte un immense réservoir numérique capable d’engloutir des quantités massives d’informations issues de diverses sources.
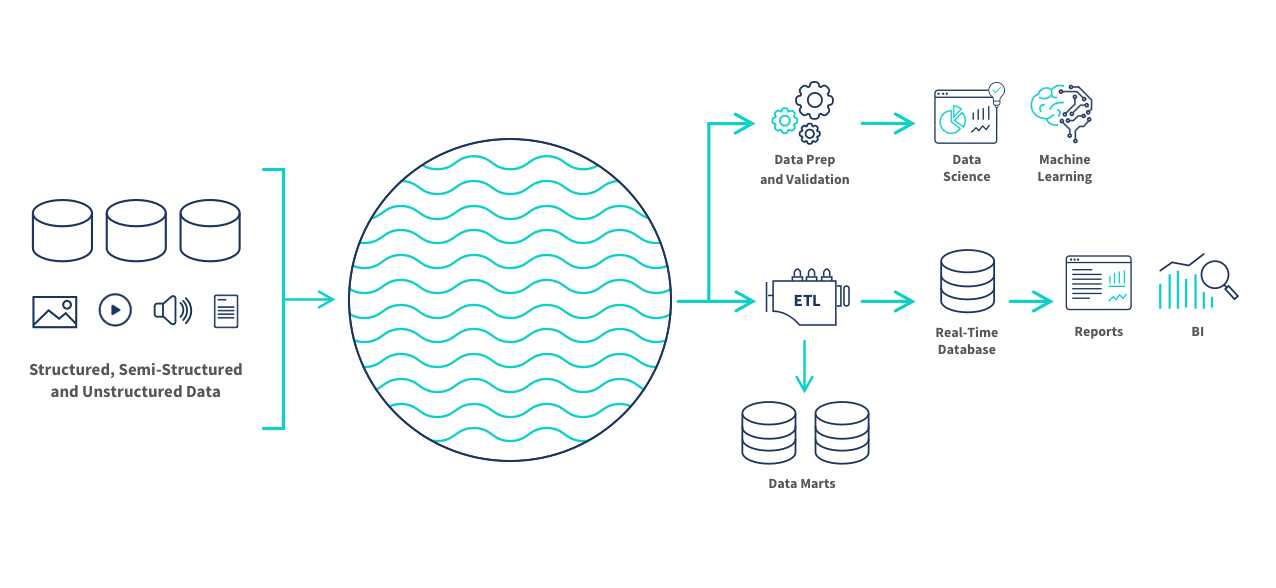
Une caractéristique essentielle du Data Lake est qu’il ne fait pas de distinction entre les données structurées (comme des tableaux ou des bases de données), semi-structurées (comme des fichiers XML ou JSON) et non structurées (comme des images, des vidéos ou des documents textes).
Toutes ces données peuvent être stockées ensemble dans leur forme brute, sans avoir à être préalablement traitées ou organisées selon un modèle prédéfini.
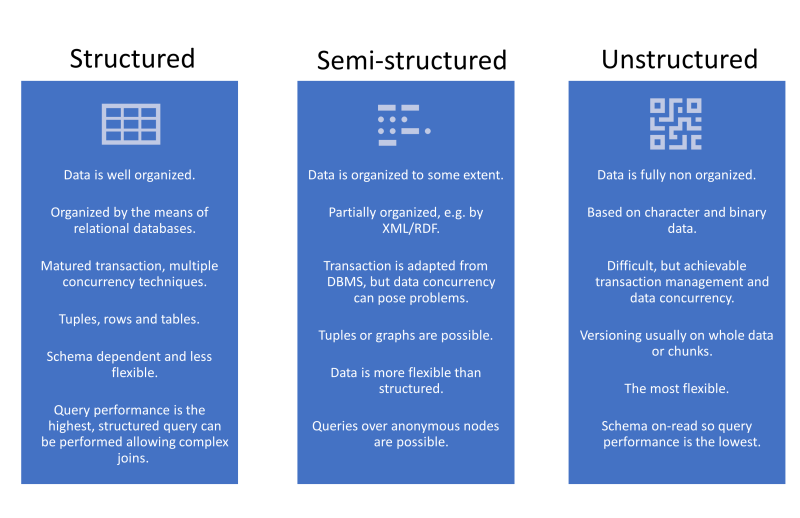
C’est là une différence fondamentale avec un entrepôt de données classique (Data Warehouse), qui au contraire exige que les données soient structurées et « nettoyées » avant de pouvoir être chargées. Avec un Data Lake, on adopte une approche « schema-on-read » : la structure et le sens des données ne sont définis qu’au moment de leur utilisation, et non lors de leur stockage initial.
Pour filer notre métaphore, disons qu’un Data Warehouse s’apparente à une usine de mise en bouteille qui traite et conditionne l’eau avant de la stocker, tandis qu’un Data Lake se contente de recueillir toute l’eau disponible, sans traitement préalable, pour permettre autant d’usages ultérieurs imaginables.
Cette flexibilité est l’un des principaux atouts du Data Lake. Le fait de conserver les données brutes permet de préserver tout le potentiel informatif des données pour des cas d’usage futurs, ce qui inclue évidemment ceux auxquels on n’aurait pas pensé initialement. C’est un peu comme si on pouvait remonter le temps et accéder à l’eau du lac dans son état d’origine, avant tout traitement.
Différences entre Data Lake, Data Warehouse et Data Lakehouse
Maintenant que nous avons clarifié ce qu’est un Data Lake, creusons un peu plus les différences avec les concepts voisins de Data Warehouse et de Data Lakehouse.
Le Data Warehouse, comme vous le savez peut-être déjà, est une base de données orientée sujet, organisée pour que des utilisateurs métier puissent analyser les données selon des axes prédéfinis. C’est un peu comme une bibliothèque où les livres seraient rangés par thème et par auteur pour faciliter la recherche. Dans un Data Warehouse, les données sont structurées, filtrées et agrégées en amont pour répondre à des besoins d’analyse identifiés.
À l’inverse, encore une fois, le Data Lake adopte une approche plus flexible et exploratoire. Il stocke les données brutes de manière peu coûteuse, sans schéma prédéfini, le tout en vue de permettre des analyses a posteriori. C’est un peu comme un grand grenier où l’on entasserait des objets hétéroclites pour éventuellement leur trouver une utilité plus tard.
C’est pour cette raison que le Data Lake est adapté à la data science et à la découverte de nouvelles informations alors qu’à l’inverse le Data Warehouse répond à des questions business connues.
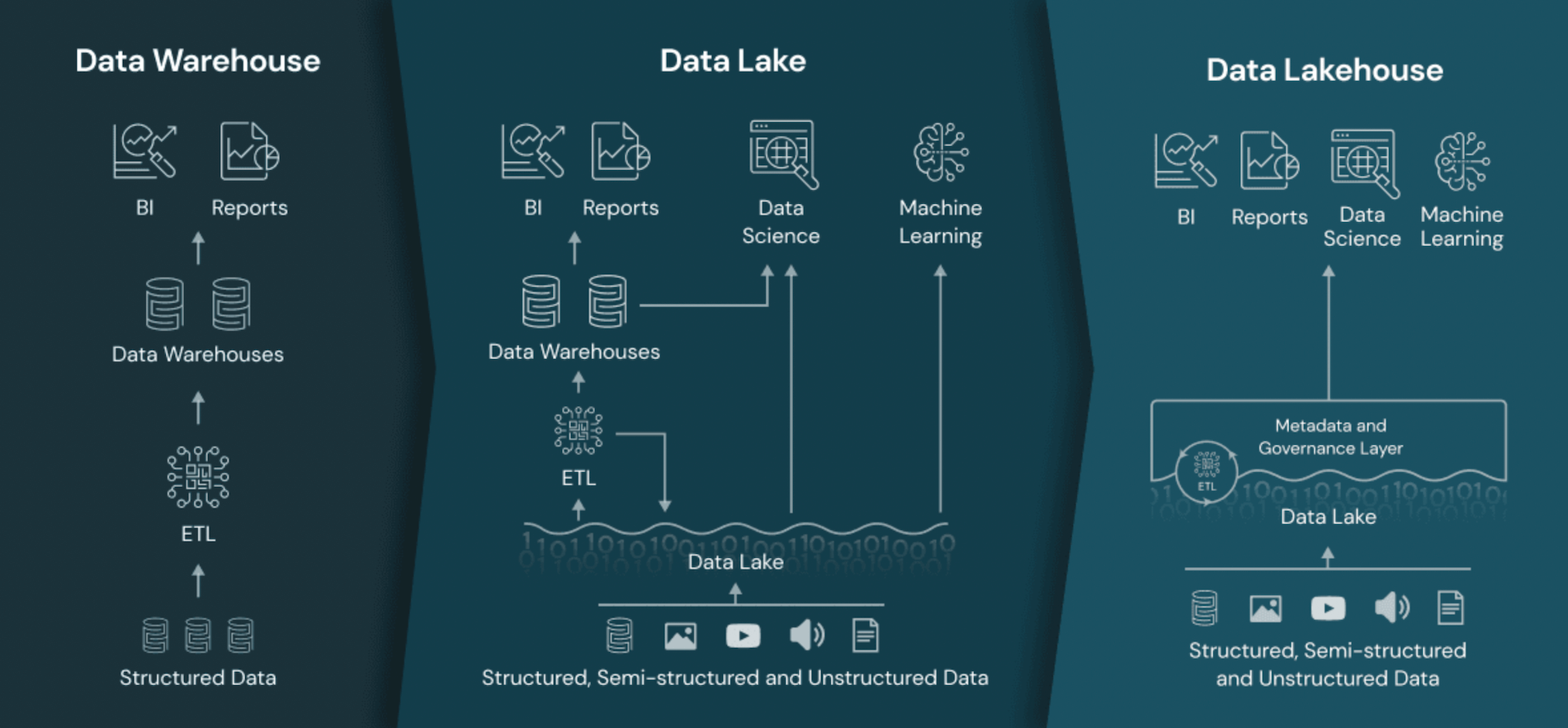
Ajoutons qu’une tendance récente consiste à combiner les atouts de ces deux approches dans ce qu’on appelle un Data Lakehouse. En résumé, il s’agit d’appliquer au Data Lake certains principes du Data Warehouse en matière de gouvernance, de sécurité et de gestion des métadonnées.
L’idée est de structurer les données du lac pour faciliter leur exploitation par des outils d’analyse traditionnels, tout en préservant la flexibilité du stockage des données brutes. C’est un peu comme si on construisait une bibliothèque dans notre grenier, pour y mettre de l’ordre sans pour autant jeter nos vieux trésors ! (on ne se lasse pas des métaphores :)).
Comment architecturer son Data Lake ?
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisBonnes pratiques d’architecture et de gouvernance
Nous l’avons vu, le Data Lake est un formidable réservoir de données brutes au potentiel analytique quasi illimité. Mais pour éviter qu’il ne se transforme en marécage inextricable, il faut l’architecturer et de le gouverner.
Voici quelques bonnes pratiques pour architecturer son Data Lake :
1 – Cataloguer les données
Il est essentiel de tenir un inventaire précis de toutes les données présentes dans votre Data Lake. Cela implique de documenter leur provenance, leur format, leur contenu, leur niveau de qualité et de confidentialité et leur date d’intégration et de mise à jour.
Il existe des outils, comme le français Data Galaxy, pour automatiser ce suivi et faciliter la recherche d’informations dans votre Data Lake via un moteur de recherche et des taxonomies métier.

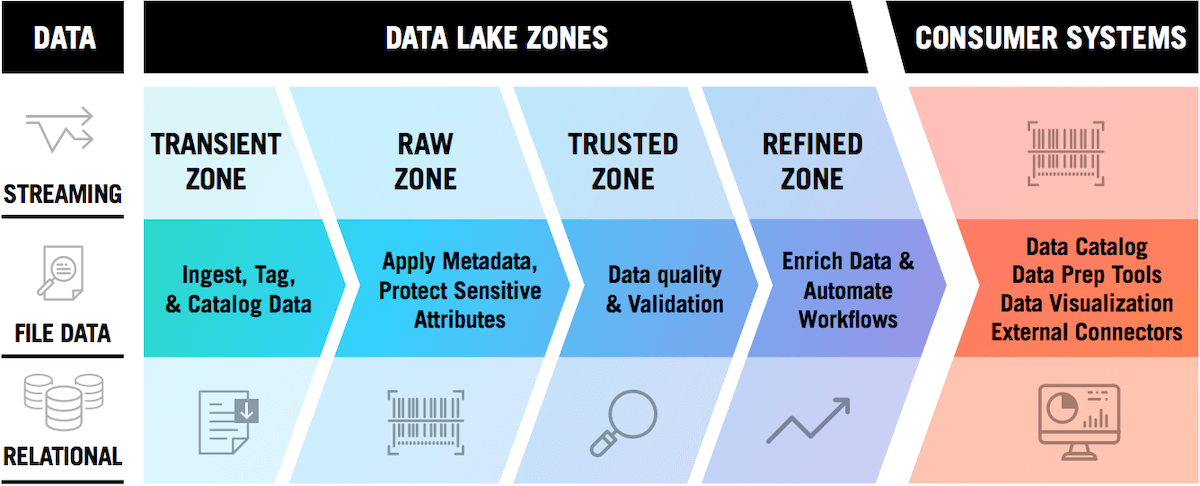
2 – Zoner le Data Lake

Une autre bonne pratique consiste à structurer le Data Lake en plusieurs zones pour isoler les données en fonction de leur niveau de qualité, de leur degré de transformation et de leur usage.
Classiquement, on distingue :
- Une zone « rawdata » pour les données brutes, non transformées.
- Une zone « trusted » pour les données validées et labellisées.
- Une zone « refined » pour les données enrichies et prêtes pour l’analyse.
- Une zone « sandbox » pour les données expérimentales et les tests.
Ce zonage permet d’appliquer des règles de sécurité et de cycle de vie adaptées à chaque type de données.
3 – Sécuriser les accès
La sécurité est un enjeu majeur du Data Lake – lequel contient bien souvent des données sensibles. Il est important de mettre en place une matrice de droits pour contrôler finement qui peut accéder à quoi, en fonction du profil et du besoin d’accès de chaque utilisateur. Les principes du moindre privilège et du contrôle permanent doivent être appliqués. Les accès doivent être tracés et audités régulièrement.
4 – Contrôler la qualité des données
Il faut aussi mettre en place des contrôles de qualité des données à chaque étape du pipeline d’ingestion dans le Data Lake :
- Des règles de validation doivent être définies pour vérifier l’intégrité, la cohérence et la complétude des données.
- Des processus de nettoyage et de réconciliation permettent de traiter les anomalies et les doublons.
- Des indicateurs de qualité doivent être établis et suivis pour chaque jeu de données critique.
5 – Gouverner le cycle de vie des données
Il faut enfin définir une politique de gestion du cycle de vie des données dans le Data Lake. Et cela passe par la définition de règles d’archivage et de purge pour ne pas conserver indéfiniment des données obsolètes ou inutiles.
Ces pratiques relèvent de la gouvernance des données, qui doit être animée conjointement par la DSI et les métiers.
Rôle du cloud dans la mise en place d’un Data Lake
Aujourd’hui, la grande majorité des Data Lakes sont déployés dans le cloud. Le cloud apporte une bien meilleure flexibilité dans le dimensionnement du Data Lake. Les capacités de stockage et de traitement peuvent être ajustées à la volée en fonction des besoins, sans avoir à investir dans des serveurs physiques.
Et les principaux fournisseurs cloud comme AWS, Azure ou GCP proposent des services managés qui simplifient considérablement le déploiement et l’administration du Data Lake.
Lorsqu’on choisit le cloud, plus besoin de se soucier de l’infrastructure, on se concentre sur la valorisation des données. L’écrasante domination du cloud aujourd’hui ne concerne d’ailleurs pas que les Data Lakes, mais aussi les Data Warehouses et toutes les autres technologies de stockage de données.
Construire un Data Lake en local est devenu une idée étonnante…
Outils et technologies pour construire son Data Lake
Il existe un large écosystème d’outils et de technologies pour pour mettre en œuvre un Data Lake – des technos et des outils souvent open source d’ailleurs, qui couvrent les différentes étapes du cycle de vie des données :
- Ingestion des données. Vous pouvez utiliser des outils comme Apache Nifi, Flume ou Kafka Connect pour collecter en temps réel les données provenant de sources diverses (bases de données, fichiers plats, APIs, IoT…) et les importer ensuite dans le Data Lake. Ils gèrent le découpage en lots, la compression et le formatage des données. Des outils de type ETL (Extract Transform Load) comme Talend ou Informatica peuvent également être utilisés pour intégrer des données structurées.
- Stockage des données. Le stockage des données dans un Data Lake s’appuie sur des systèmes de fichiers distribués comme HDFS (Hadoop Distributed File System), S3 (Simple Storage Service) sur AWS ou ADLS (Azure Data Lake Storage). Ces systèmes assurent la scalabilité, la résilience et la sécurité du stockage. Les données sont stockées dans des formats optimisés pour l’analyse, que ce soit Parquet, Avro ou ORC.
- Traitement des données. Plusieurs frameworks sont utilisés pour traiter et analyser les données du Data Lake, notamment Apache Spark qui permet de faire du traitement batch et streaming de gros volumes de données. Spark SQL permet d’interroger les données avec des requêtes de type SQL. Des notebooks comme Jupyter ou Zeppelin sont souvent utilisés par les data scientists pour explorer les données de manière interactive.
- Accès aux données. Pour démocratiser l’accès aux données du lac, des outils de data viz et de BI comme Tableau, PowerBI ou Qlik permettent aux utilisateurs métier de créer facilement des rapports et des tableaux de bord à partir des données préparées. Dans la famille des outils au service de la démocratisation des données, on trouve aussi les langages de requêtes comme Hive ou Impala qui permettent d’interroger les données avec une syntaxe proche du SQL. Des outils de type « data catalog » comme Collibra ou Alation permettent, de leur côté, de référencer et documenter les jeux de données disponibles.
- Administration et sécurité. Enfin, pour opérer un Data Lake, il faut disposer d’une solution de gestion des metadonnées et de data lineage comme Apache Atlas ou Cloudera Navigator. Concrètement, ces outils permettent de suivre l’origine et l’utilisation de chaque jeu de données. Sur le volet administration & sécurité, citons aussi les solutions de sécurité comme Apache Ranger ou Sentry (pour gérer finement les autorisations d’accès) et les solutions de data quality comme Talend DQ ou Informatica IDQ (pour mesurer et améliorer la qualité des données)..
Le choix et l’assemblage de ces différents outils dépend évidemment du volume de données, des cas d’usage et de l’environnement existant de chaque entreprise. L’enjeu est d’adopter une architecture évolutive et cohérente, alignée sur la stratégie data à long terme.
Si vous vous intéressez aux sujets data, nous vous conseillons ces articles complémentaires :
Laisser un commentaire