L’essentiel :
- Outils ETL Cloud: Des solutions comme StichData, Fivetran et Xplenty offrent une variété de connecteurs et une intégration robuste avec diverses sources.
- Solutions ETL « on premise »: Informatica PowerCenter, SAS et Microsoft SSIS dominent le marché avec une profondeur fonctionnelle et une flexibilité pour divers projets.
- Outils ETL open source: Apache AirFlow, Apache Kafka, Cloudera Data Hub (CDH) et Talend ETL sont des outils clés pour la gestion et l’intégration des données.
- ETL vs ELT: Comprendre la différence entre ETL et ELT est essentiel pour choisir la bonne stratégie d’intégration des données.
Il existe grosso modo 3 familles d’ETL dont nous allons vous présenter dans cet article quelques représentants emblématiques.
| Type d'ETL | Description | Avantages | Inconvénients |
|---|---|---|---|
| ETL Cloud | Les ETL Cloud sont des services hébergés (SaaS) qui gèrent l'intégration des données entièrement en ligne. Ils ne nécessitent pas d'infrastructure physique, s'appuyant sur des infrastructures cloud pour traiter les données de manière flexible et évolutive. Ces solutions sont idéales pour les entreprises cherchant à réduire les coûts initiaux et à bénéficier d'une mise en œuvre rapide. Les ETL Cloud font partie des composantes clés des stacks data modernes. |
|
|
| ETL On Premise | Les ETL On-Premise sont des solutions installées localement sur l'infrastructure physique de l'entreprise. Elles offrent un contrôle total sur le processus d'intégration des données et sont souvent choisies par les organisations ayant des exigences strictes en matière de sécurité et de conformité. Malgré tout, la cloudification des infrastructures data rend ce type de solutions de moins en moins utilisé. |
|
|
| ETL Open Source | Les ETL Open Source sont des logiciels dont le code source est accessible à tous. Ils sont hautement personnalisables et sont souvent choisis pour leur flexibilité et leurs coûts réduits. Ces outils sont soutenus par des communautés actives et sont constamment améliorés. |
|
|
Sommaire
Les outils ETL Cloud
Commençons par les ETL Cloud. Ces solutions ont commencé à se développer au milieu des années 2000. Elles ont l’avantage d’être plus légères et moins coûteuses que les ETL traditionnels. Comme toutes les solutions SaaS, le modèle économique est celui de l’abonnement. Les ETL Cloud ont le vent en poupe, ils surfent sur une tendance très forte : le Cloud.
De plus en plus de projets data sont montés sur le cloud, en associant un DWH Cloud et un ETL Cloud. Cette architecture offre en général plus de souplesse, une plus grande vitesse de processing (real-time), des intégrations plus simples à mettre en place…
StichData
Stitch Data, racheté par Talend pour près de 60 millions de dollars, est l’un des leaders sur le marché des ETL Cloud. Il peut être relié à un nombre assez varié de destinations : Amazon RedShift (le service de Data Warehouse d’Amazon), BigQuery, Snowflake…D’un autre côté, Stitch peut se brancher avec un nombre considérable d’applicatifs SaaS et de bases de données.
L’un des grands avantages de Stitch, c’est que l’éditeur a développé un module Open Source (appelé Singer) qui permet aux utilisateurs de la communauté de développer de nouveaux connecteurs. Cela permet d’augmenter continuellement le nombre de connecteurs disponibles. Stitch met également une API et des web apps à destination de ses clients.
Le plan standard commence à 100 dollars par mois pour 5 millions de lignes, 500 dollars pour 50 millions de lignes, 1000 dollars pour 200 millions de lignes…
Fivetran
Fivetran est une solution plus robuste que Stitch. Elle s’intègre avec un plus grand nombre de sources et de bases cibles (Snowflake, Redshift, BigQuery, Azure). Fivetran permet d’aller un peu plus loin dans la transformation des données, de délivrer au Data Warehouse des données plus consistantes et cohérentes. Le support est également réputé pour être très réactif et très professionnel.
Fivetran propose un plan gratuit jusqu’à 500 000 lignes par mois. Le détail des plans payants n’est pas public.
Xplenty
Xplenty est un autre intégrateur de données réputé, aux possibilités d’intégration très grandes. Quelques chiffres : à l’heure où ces lignes sont écrites, SnowXplenty propose des connecteurs avec 20 bases de données (Snowflake, Microsoft Azure, Oracle, PostgreSQL, MS SQL, Google BigQuery…), 5 bases de données Cloud (Amazon S3, Google Cloud Storage, HDFS…), plus de 100 applicatifs cloud, une dizaine d’outil d’analytics, une dizaine d’outils publicitaires (Facebook Ads, Bing Ads, AdWords…), 3 BI, etc.
Le support client, comme celui de Fivetran, est très réputé. Xplenty facture en fonction du nombre de connecteurs. Les tarifs sont assez élevés : 15 000 dollars pour la formule Starter qui inclut 2 connecteurs (+ 2 000 dollars par an en plus par connecteur supplémentaire).
Découvrez pourquoi les Customer Data Platforms vont s’imposer dans les prochaines années.
Les solutions ETL « on premise »
Pour ceux qui ne sont pas familiers du terme (on sait jamais), les logiciels « on-premise » désignent tous les logiciels « à installer ». Ils sont installés directement sur les serveurs de l’entreprise par opposition aux logiciels Cloud / SaaS qui sont installés sur des serveurs distants gérés par les éditeurs.
La différence porte sur la localisation des serveurs (qui a beaucoup d’incidence sur les questions de contrôle, d’accès, de sécurité, de maintenance…) mais aussi sur le modèle économique. Les logiciels on premise utilisent le modèle de la licence, renouvelée tous les ans, contrairrement aux logiciels SaaS qui utilisent le modèle de l’abonnement (mensualisé ou annualisé).
Les solutions on-premise sont les représentants historiques du marché des ETL. Ce sont, comme on l’a vu, les solutions les plus lourdes, les plus complexes à utiliser et les plus chères. Pour le coût de la licence, comptez au minimum 50k – 100k par an. A ce coût doivent s’ajouter les coûts élevés d’installation et de formation (il y a une grosse courbe d’apprentissage). A noter que la plupart des éditeurs historiques d’ETL On-Premise ont embrassé la révolution cloud et proposent AUSSI des ETL Cloud qui ont sans doute vocation à remplacer à terme les ETL On Premise…
Gartner a conçu un quadrant qui permet de visualiser les différents acteurs et leur répartition d’après deux axes : la simplicité/complexité d’utilisation ; la richesse fonctionnelle. Nous le reproduisons :
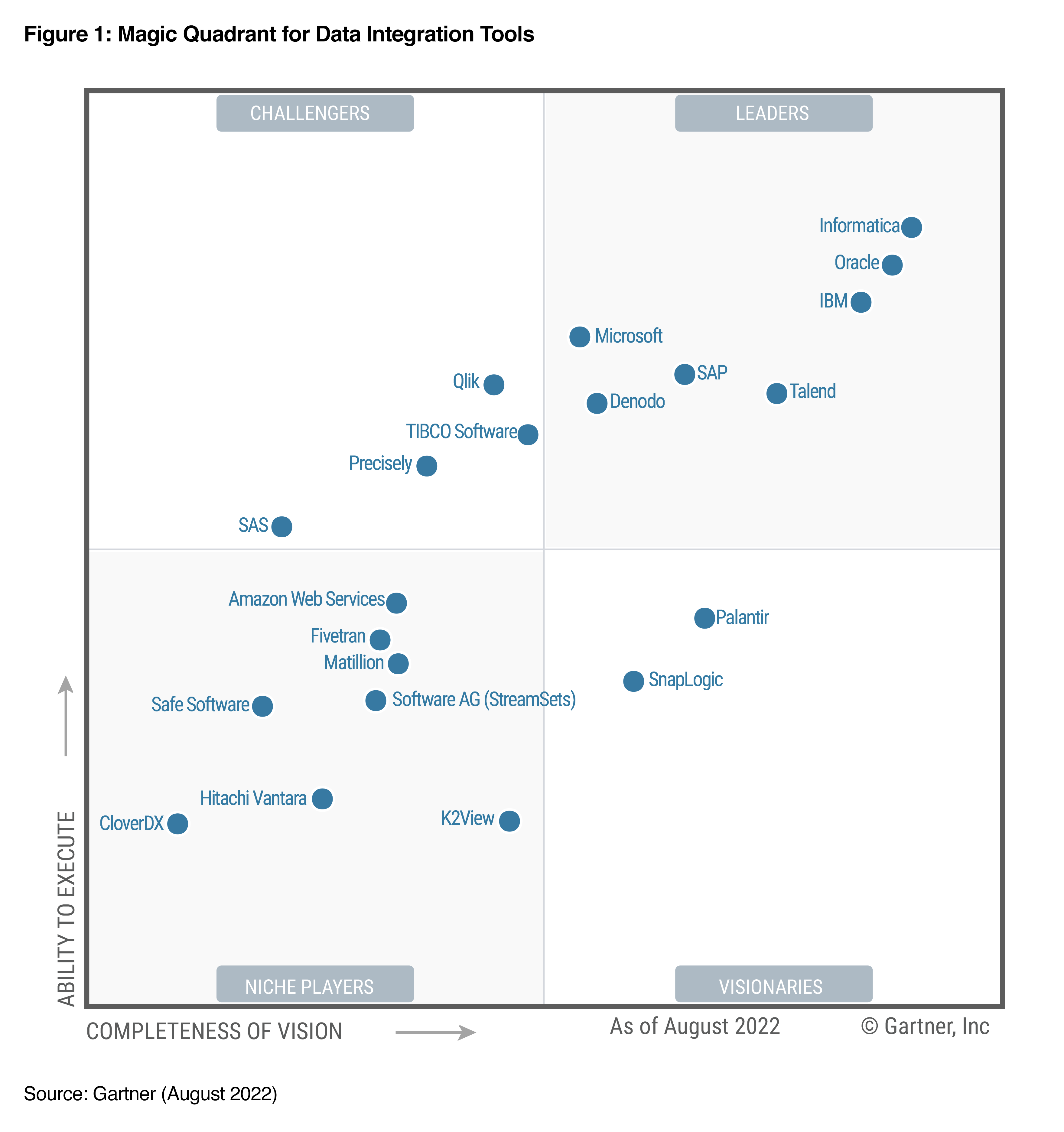
Nous avons sélectionné 3 solutions : Informatica PowerCenter, SAS et Microsoft SSIS.
Informatica PowerCenter
Informatica PowerCenter reste LE leader du marché des ETL on premise. L’outil dispose d’une très grande profondeur fonctionnelle, est entièrement scalable, affiche des performances de premier de la classe. Il peut être utilisé pour tous les projets liés à de l’intégration de données : gouvernance des données, migration de données, entreposage de données, replication et synchronisation de données, Master Data Management (MDM), etc.
Informatica cible les grandes organisations et s’adresse aux entreprises souhaitant développer de gros projets data. Informatica permet vraiment de compiler toutes les données de l’entreprise. Il gère toutes les sources.
PowerCenter gère aussi bien le batch que le temps réel, propose un gestionnaire de meta-données, des outils de Data Visualization. Informatica est constitué de trois principaux composants : une interface client qui permet de gérer les meta-données, le répertoire, de définir les règles métiers, etc. ; un répertoire qui stocke toutes les données ; un serveur connecté aux sources et aux bases cibles où sont transformées et chargées les données. Informatica est un mastodonte. C’est sans doute la solution la plus onéreuse du marché…
SAS
La société SAS, basée en Caroline du Nord, propose une suite d’outils d’outils d’intégration de données : SAS Data Management, SAS Data Integration Server, SAS Federation Server, SAS/ACCESS, SAS Data Loader for Hadoop, SAS Event Stream Processing.
Ces outils sont particulièrement flexibles et s’adaptent à tous les types et toutes les tailles de projet. Pour cette raison et la très grande qualité du service client / de la maintenance, les clients de SAS sont souvent des clients fidèles.
SAS est une société très innovante, qui s’adapte rapidement aux évolutions et tendances du Big Data. SAS a par exemple intégré très tôt des fonctions de Machine Learning pour identifier des schémas de données. Les possibilités d’intégration sont également très élevées. Très doué sur le volet analytics, SAS supporte en revanche un spectre de use cases un peu plus étroit que ses concurrents.
Microsoft SSIS
Le SQL Server Integration Services (SSIS) est l’outil ETL développé par Microsoft. Il s’agit d’un outil très complet qui permet de gérer les synchronisations, les migrations de données, leur transformation et leur intégration dans le Data Warehouse. SSIS peut extraire des données de différentes sources et de différents formats : bases de données relationnelles / transactionnelles, fichiers csv, xml, txt, FTP, applications, etc.
Il est possible de créer des connecteurs sur-mesure. Les possibilités en termes de transformation sont vraiment très grandes. SQL Server Integration Services est apparu en 2005 comme une composante de Microsoft SQL Server. Il a remplacé le précédent ETL de Microsoft : Data Transformation Services (DTS). L’un des avantages de SSIS, c’est qu’il est très simple et rapide à implémenter et à intégrer avec les services Azure. La documentation est d’ailleurs accessible en français.
Si vous vous intéressez aux sujets data, ces articles pourraient aussi vous intéresser :
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisLes outils ETL open source
Passons, pour finir, à la dernière catégorie : les logiciels ETL open source. Ils constituent une alternative intéressante aux solutions propriétaires – une alternative gratuite (attention toutefois à ne pas oublier les coûts de déploiement…). Leur développement est associé à celui des solutions de Business Intelligence open source (OSBI) : Pentaho, SpagoBI, JasperIntelligence…
L’utilisation de ces solutions est en revanche plus complexe que les outils ETL Cloud et la connectivité est souvent moins développée, même si, open source oblige, libre à vous de développer des connecteurs spécifiques…Nous avons sélectionné 4 outils : Apache AirFlow, Apache Kafka, Cloudera et Talend ETL
Apache AirFlow
Construit sous Python, Apache Airflow est un outil d’automatisation de workflows et de planification qui peut être utilisé pour concevoir et gérer des pipelines de données. Airflow n’est pas à proprement parler une plateforme de gestion des flux de données. Les « tâches » représentent des mouvements de données, mais elles ne déplacent pas les données en tant que telles.
Ce n’est pas un outil ETL « interactif ». Il existe un grand nombre de plugins permettant d’ajouter des fonctionnalités, de renforcer la connectivité avec des plateformes de stockage (de type Amazon RedShift, MySQL…) et de manipuler de manière plus complexe les données et meta-données. Apache Airflow propose par ailleurs des connecteurs avec Amazon Web Services (AWS) et Google Cloud Platform (GCP) (qui inclut BigQuery).
Apache Kafka
Apache Kafka a été développé en 2012 au sein de l’incubateur Apache, comme Apache Airflow. Au départ, il s’agit d’une plateforme de streaming distribuée open source. Mais, avec le temps, les cas d’usage se sont considérablement élargis.
Aujourd’hui, Kafka est une plateforme permettant de centraliser le stockage et l’échange en temps réel de l’ensemble des données de l’entreprise. Kafka est beaucoup utilisé pour mettre en place des process ETL en temps réel. Pour l’extraction et le chargement, on utilise la brique Kafka Connect ; pour la transformation, on utilise Kafka Streams.
Cloudera Data Hub (CDH)
Cloudera est l’un des premiers pure-players à s’être emparés d’Hadoop, un framework libre et open source écrit en Java. L’éditeur a développé plusieurs solutions commerciales mais soutient aussi un certain nombre de projets open source Hadoop, donc CDH. CDH est l’une des distributions Hadoop les plus complètes, testées et populaires. Cloudera permet d’utiliser le framework Hadoop au meilleur de ses capacités. L’un des cas d’usage de Cloudera Data Hub est la construction de process ETL.
Talend ETL
Talend est un éditeur de logiciels français qui développe des solutions propriétaires et des produits open source, parmi lesquels Open Studio, un logiciel d’intégration des données qui est aussi le produit historique de la marque. OpenStudio permet de disposer d’un outil ETL relativement simple à implémenter et très complet. Il propose notamment une belle variété de connecteurs avec des système de gestion de bases de données (Oracle, Teradata, Microsoft SQL Server…), des logiciels SaaS CRM & Marketing (Marketo, Salesforce…), des suites (SAP, Microsoft Dynamics, Sugar CRM)…
Introduction aux ETL
Définition d’un ETL
L’acronyme « ETL » appartient à l’univers du Data Marketing. Avant de vous présenter les différents types d’ETL du marché, il n’est pas inutile de prendre le temps de définir clairement en quoi consiste un ETL. Par où commencer ? Partons des trois lettres qui composent cet acronyme :
- E, pour Extract (Extraire).
- T, pour Transform (Transformer).
- L, pour Load (Charger).
Cet acronyme, en un sens, dit déjà tout ! L’ETL est un process par lequel « on » extrait dans un premier temps les données, on les transforme et, enfin, on les charge. Cela ne nous fait pas beaucoup avancer. Ne vous inquiétez pas, vous allez y voir plus clair dans quelques lignes.
Au-delà, ETL désigne aussi les outils permettant de réaliser ce process. C’est pour cette raison que notre article est consacré aux outils ETL, aux outils qui permettent de mettre en place un process ETL. Voici une manière de représenter la place et le rôle d’un ETL dans une architecture IT. Le schéma est proposé par Informatica, l’un des leaders (voire LE leader) du marché des ETL on-promise :
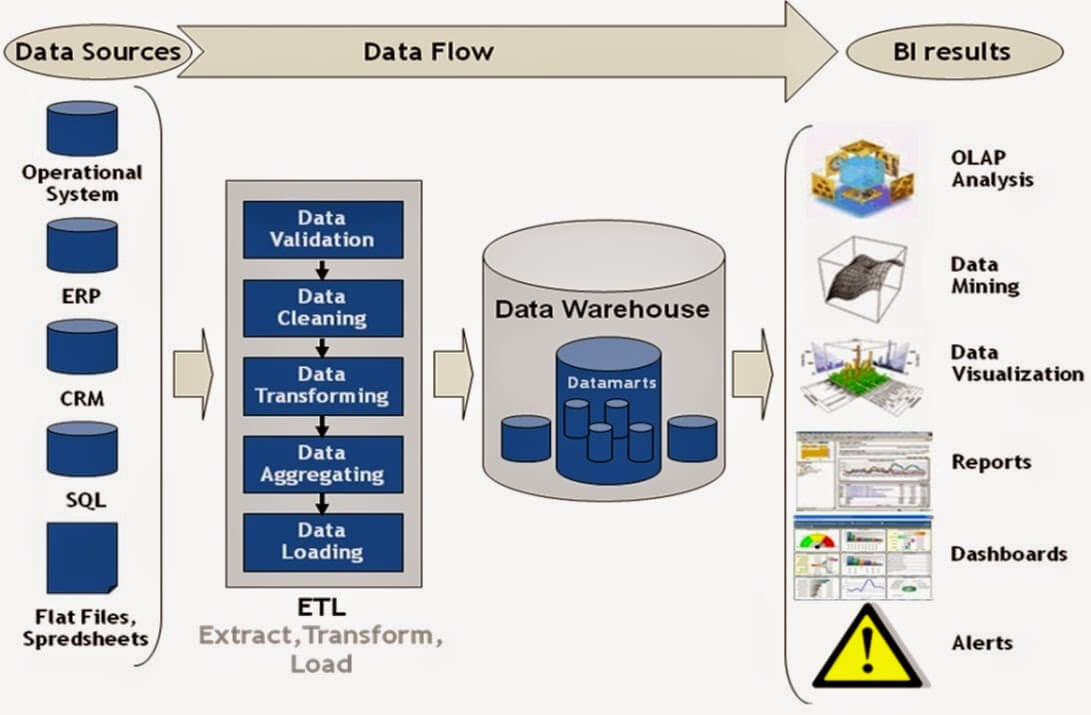
Revenons sur les trois étapes de ce process :
Ingérer toutes les données… [Extract]
La première phase du process ETL est l’extraction des données. L’entreprise dispose d’un grand volume de données issues de ses différentes sources : site web, ERP, CRM, Data Warehouse, etc. Ces données sont hétérogènes et dispersées. C’est ici que la composante « E » de l’ETL entre en jeu. Les outils ETL sont conçus pour « extraire » les données de leurs sources originales.
Cette extraction n’est ni aléatoire ni exhaustive; elle est généralement ciblée et régie par des règles prédéfinies. Les entreprises peuvent définir des paramètres spécifiques, comme les sources à prioriser ou la fréquence de rafraîchissement des données, guidant ainsi le processus d’extraction pour répondre au mieux à leurs besoins spécifiques.
Découvrez comment choisir le bon type de base de données pour son projet d’entreprise.
…Les transformer…[Transform]
L’étape T du process ETL fait référence à toutes les étapes de transformation des données extraites des sources en vue de leur intégration dans la plateforme de données cible. Cette phase peut inclure le nettoyage, la validation, et la restructuration des données, assurant leur cohérence et leur pertinence pour les besoins de l’entreprise.
Les solutions ETL basées sur le cloud, souvent considérées comme des synchronisateurs plutôt que comme des transformateurs, se concentrent en général sur le déplacement des données, avec une transformation minimale. Il faudrait plutôt parler d’outil « EL ». Les solutions ETL on-premise et open source, bien qu’offrant une plus grande flexibilité et des options de transformation plus robustes, sont généralement plus coûteuses et plus complexes à gérer.
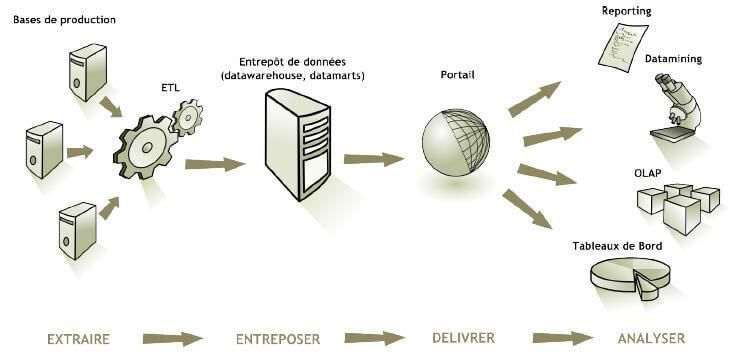
…Les charger dans une base de données (un Data Warehouse par exemple) [Load]
L’étape finale de l’intégration des données via le processus ETL est le chargement des données transformées et correctement formatées dans la plateforme de données cible : Data Warehouse, CDP, etc. Ce processus peut être effectué en une seule fois (chargement complet) ou à des intervalles programmés (chargement incrémentiel), et cela peut être réalisé via des chargements par lots ou en continu.
Le chargement par lots se produit lorsque le logiciel ETL extrait des lots de données d’un système source, généralement selon une fréquence définie (par exemple, toutes les heures). En revanche, l’ETL en continu, également connu sous le nom d’ETL en temps réel ou de streaming de données, est une méthode alternative où les données sont ingérées par le pipeline de données dès qu’elles sont disponibles dans le système source.
Le choix du mode de traitement dépend du cas d’utilisation spécifique de l’entreprise. Par exemple, le chargement en streaming (en continu) est recommandé pour les cas d’usage temps réel : trading haute fréquence, personnalisation web…
Découvrez notre comparaison entre les approches traditionnelle et Cloud pour une architecture Data Warehouse.
Petit rappel sur l’histoire des ETL
Profitons-en d’ailleurs, pour faire un petit aparté sur l’histoire des outils ETL. C’est dans les années 1970 que se sont développés les premiers logiciels ETL.
Ils ne sont donc pas nés de la dernière pluie. A cette époque, les entreprises commençaient à utiliser plusieurs sources de données, à gérer différentes bases pour stocker différentes sortes de données business. Très tôt, le besoin s’est fait sentir d’agréger ces données (la problématique de l’éparpillement des données n’est donc pas nouvelle elle non plus…).
C’est de là que sont nés les outils ETL : ils sont apparus pour processer toutes les données stockées par les entreprises, les transformer avant de les charger dans un outil cible. Au tournant des années 1980 – 1990, un type d’outil particulier s’est imposé comme solution de référence pour recevoir toutes ces données transformées et faire office de référentiel data : le Data Warehouse.
Base de données d’un type particulier, le Data Warehouse permettait aux entreprises d’avoir accès aux données en provenance de tous les systèmes : les ordinateurs centraux, les micro-ordinateurs, les ordinateurs personnels, les feuilles de calcul, etc.
En général, à cette époque, les entreprises utilisaient souvent plusieurs Data Warehouses et plusieurs ETL. Les organisations finissaient par se retrouver avec un ensemble d’outils ETL non intégrés entre eux. L’avantage, c’est que cela a contribué à l’augmentation du nombre d’éditeurs de logiciels ETL, à l’augmentation de la concurrence et donc à la diminution des prix. Hier réservés aux grandes entreprises, les outils ETL se sont largement démocratisés.
Zoom sur la solution Octolis,
pour croiser et synchroniser vos données clients.
Octolis permet de réconcilier toutes vos données clients, et de construire des segments d'audience sur mesure pour alimenter vos outils Sales et Marketing.
Vos équipes vont enfin pouvoir tirer le plein potentiel des données que vous collectez.
En savoir plus sur OctolisETL VS ELT : Quelles différences ?
ETL (Extract, Transform, Load) et ELT (Extract, Load, Transform) sont deux approches distinctes d’intégration de données, chacune avec ses propres caractéristiques uniques et adaptée à différents besoins en matière de données.
La différence fondamentale entre les deux est la séquence des étapes de transformation et de chargement : l’ETL transforme les données avant de les charger dans la destination finale, tandis que l’ELT charge d’abord les données et effectue ensuite les transformations nécessaires directement dans la base de données cible.
L’ETL est souvent privilégié pour les scénarios nécessitant des transformations intensives ou une conformité stricte, car il permet de manipuler les données avant qu’elles n’atteignent la base de données cible, réduisant ainsi le risque de transférer des données non conformes. Cependant, cette méthode peut ralentir le processus d’ingestion des données car elles doivent être transformées avant le chargement.
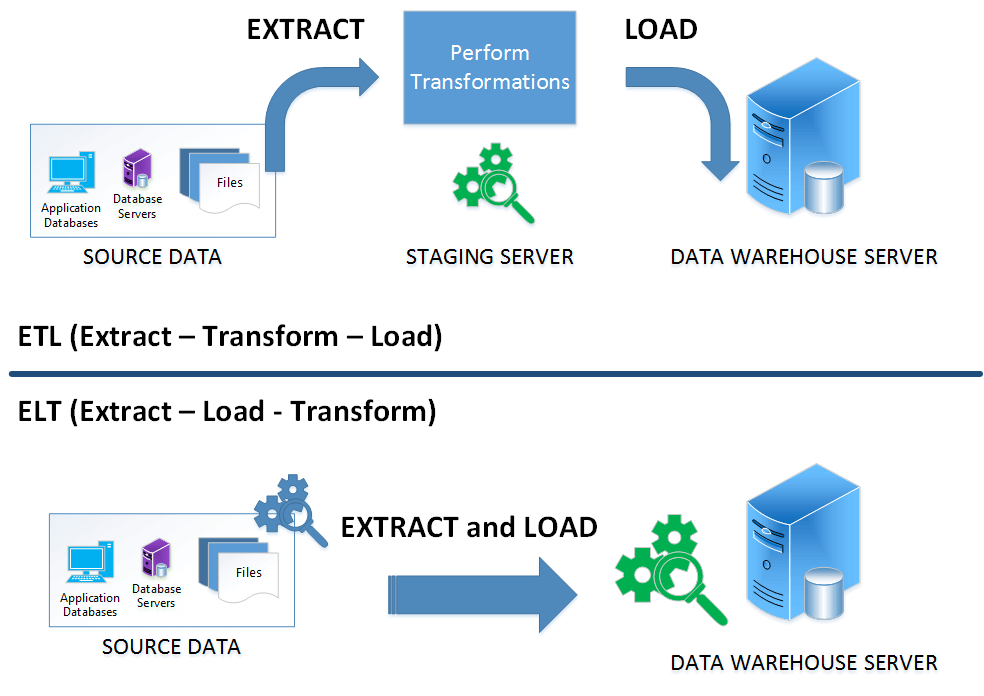
D’autre part, l’ELT est avantageux lorsque les performances et la rapidité sont prioritaires. Les données sont rapidement chargées dans la destination, et les transformations ont lieu après, permettant une ingestion plus rapide des données. Cette méthode est de plus en plus populaire avec l’adoption croissante des infrastructures cloud, car elle permet des transformations flexibles et l’exploration de données en utilisant des ensembles de données complets.
Le choix entre ETL et ELT dépendra des besoins spécifiques de l’entreprise, des objectifs, de la nature des données, et des exigences en matière de conformité. Bien que l’ELT gagne en popularité, l’ETL reste pertinent pour de nombreux cas d’utilisation, en particulier là où la sécurité des données et la conformité sont de la plus haute importance.
Les différents types d’outils ETL
Un petit mot avant de commencer à vous présenter plusieurs solutions ETL. Il faut être conscient qu’il existe plusieurs types de logiciels ETL, plusieurs catégories. Au départ, ces différences peuvent ne pas être évidentes. On a tendance à penser que tous les ETL délivrent la même promesse.
Ce qui, jusqu’à un certain point, est vrai, mais il faut aller plus loin dans l’analyse. Le point commun de tous les ETL, c’est qu’ils permettent d’extraire les données à partir de toutes les sources de données et de les charger sur des Data Warehouse divers et variés. Mais les éditeurs n’utilisent pas la même approche. Grosso modo, on peut répartir les outils ETL en deux grandes catégories :
- Il y a ceux, premièrement, qui sont orientés sur la synchronisation des données. Ce sont des synchronisateurs. Ils permettent de mettre en place des setups et des workflows permettant de faire circuler la donnée le plus rapidement possible, d’organiser les tuyaux qui relient les sources de données à la base de référence. Les interfaces utilisateurs de ce type d’outils tendent à mettre l’accent sur la visualisation du statut des synchronisations : elles visent la simplicité plus que la profondeur fonctionnelle. Leur principale principale préoccupation est moins de transformer la donnée que d’en optimiser au maximum la circulation entre les sources et la base cible. Des solutions comme Blendo, Fivetran et Stitch tendent à appartenir à cette catégorie.
- Deuxièmement, on pourrait regrouper certains ETL dans la catégorie des « transformateurs », par distinction avec celle des « synchronisateurs ». Ce sont des ETL plus évolués qui ne se contentent pas de synchroniser les données, mais permettent, en plus, de les transformer et de les enrichir. Ces outils ont, en général, un plus grand nombre d’applications et de fonctionnalités, leur structure de prix est plus complexe (basée sur le temps de calcul, le débit de données…), ils gèrent un plus grand nombre de sources de données, proposent des APIs, des log files…Cela va sans dire, ce sont des solutions souvent plus chères – aussi bien au niveau du coût d’acquisition que des coûts d’installation et de maintenance. DataVirtuality, Etleap, Keboola, Xplenty appartiennent à cette catégorie.
Il est important d’avoir en tête ces distinctions avant de se lancer dans le choix d’un outil ETL. Si vous souhaitez surtout déplacer les données en provenance de vos sources third party dans des Data Warehouse centralisés, un outil ETL est probablement ce qui convient le mieux. A l’inverse, si vous travaillez surtout avec des log files et des fichiers de stockage génériques, un ETL « transformateur » vous aidera davantage à réaliser vos analyses.
Voilà, nous espérons vous avoir éclairé sur le fonctionnement de l’ETL et la répartition des principaux acteurs. Si vous avez des questions concernant ce sujet complexe ou votre problématique IT, n’hésitez pas à nous contacter.
bonjour,
je voudrais savoir comment télécharger ETL informatica
Il n’y a pas de version gratuite téléchargeable, mais vous pouvez accéder à une version d’essai depuis cette page.
Bonjour, merci pour cet excellent article.
Je vous opter par un ETL open source qui me permet de faire l’extraction, la transformation et le chargement des données dans le Data-Warehouse en temps réel depuis ma base de données de l’entreprise. Entre Apache Kafka et Talend quelle est la meilleure solution ?
Kafka est une technologie lourde, adapté pour de gros volumes de données et du quasi-temps réel. Dans la plupart des cas, une solution comme Talend sera plus adapté au départ.
Bonjour,
Je vous remercie pour cet excellent article, si vous me permettez de vous posez une question, en fait je commence dans quelque jour une formation en BI avec un programme qui contient plusieurs spécialités (Informatica, SAS, Talend, Datastage…), j’aimerai savoir quel est l’outil le plus demander dans le marché de l’emploi ?
Bonjour Youssef
Le marché des ETL est assez fragmenté, il n’y a pas forcément une solution de référence.
En France, j’ai le sentiment que Talend est peut être la plus utilisée, mais Informatica et SAS ont encore une grosse présence dans les grands comptes.
A noter que cela vaut le coup de travailler avec des ELT nouvelle génération type Fivetran ou Stitchdata, ne serait ce que pour bien comprendre les différences entre ELT et ETL.
Bonne formation !
C’est vraiment bien expliqué, Merci !