Le choix d’une architecture cloud dépend de vos besoins business et de vos besoins technologiques. Nous allons dans cet article vous présenter quelques uns des concepts fondamentaux du cloud computing et voir qu’il existe plusieurs modèles d’architecture cloud.
Si vous réfléchissez à basculer votre architecture dans le cloud, ce guide introductif devrait vous aider à y voir plus clair parmi les concepts souvent techniques qui circulent.
Les modèles d’architectures cloud single-server (ou single-tier)
Ces modèles, comme leur nom l’indique explicitement, consiste à n’utiliser qu’un seul serveur, virtuel ou physique, contenant un serveur web, une application et une base de données. Il n’y a qu’une seule couche, qu’un seul niveau. Tous les composants du système tournent sur un serveur unique. Un exemple ? La combinaison des logiciels libres de la stack LAMP : Linux, Apache, MySQL et PHP.
Les architectures single server sont assez peu utilisées à cause des risques de sécurité qui lui sont inhérents : un problème sur l’un des outils peut compromettre tous les autres. Ces architectures sont en général déployées pour construire des environnements de développement, pour permettre aux développeurs de construire des fonctionnalités rapidement sans se prendre la tête avec les problèmes de connectivité et de communication entre différents serveurs (localisés potentiellement dans des endroits différents).
Les modèles single-site
Une architecture single-site consiste à prendre une architecture single-server et à splitter toutes les couches (web, application et BDD) dans leurs propres instances de calcul, ce qui aboutit à la création d’une architecture à 3 niveaux. Avec toutes les ressources de calcul réunies au même endroit, cela créé une architecture dite « single-site ». Il y a essentiellement deux types d’architectures single-site : redondantes et non-redondantes.
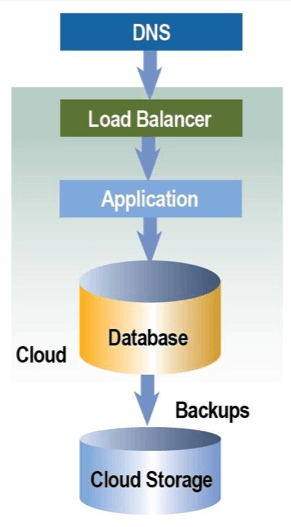
Les architectures à 3 niveaux non-redondantes
Les architectures non-redondantes à trois niveaux sont utilisées pour réduire les coûts et économiser des ressources mais sont plus risquées. En clair, une défaillance dans n’importe quel composant (un « point unique de défaillance ») peut compromettre le bon fonctionnement des flux à l’intérieur du système ou entre l’intérieur et l’extérieur. Cette approche est utilisée en général pour créer des environnements de développements / de tests. Le schéma ci-dessous représente chaque couche (ou niveau) en tant que serveur séparé, virtuel ou physique. Utiliser ce type d’architecture dans des environnements de production n’est clairement pas recommandé.
Les architectures à 3 niveaux redondantes
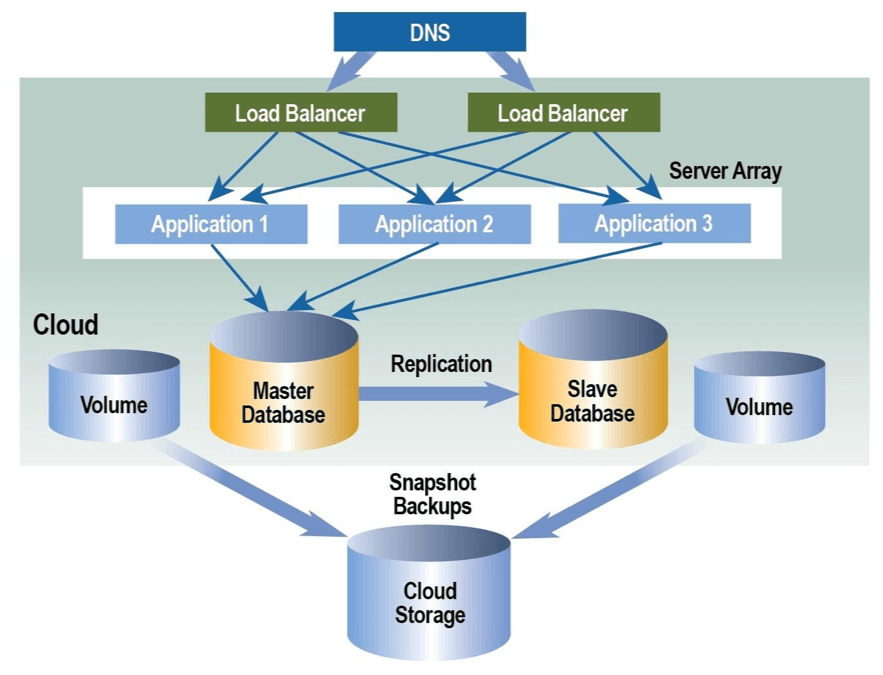
Dans une architecture redondante, chaque composant du système a un doublon. Forcément, cela contribue à complexifier l’architecture mais c’est indispensable pour garantir l’intégrité du système en cas de défaillance, de pannes. La redondance permet de s’assurer que n’importe quelle donnée est stockée dans plusieurs endroits. Construire une architecture redondante suppose de bien penser l’organisation des composants dans chaque couche, à chaque niveau (horizontal scaling) et en même temps de programmer les flux entre les couches (vertical scaling).
Si vous vous intéressez aux sujets data marketing, ces articles pourraient aussi vous intéresser :
Point unique de défaillance (single point of failure)
Les architectures cloud redondantes permettent de supprimer les points uniques de défaillance. Un point unique de défaillance, c’est un endroit dans le système dont dépend tout le reste du système, un point dont la défaillance peut entraîner le plantage de tout le système. Les points uniques de défaillance sont, par définition, non redondants. Ils représentent un risque important. Ce sont des points de fragilité du système.
Redondance vs Résilience
On confond souvent redondance et résilience. Les deux notions sont liées mais ne sont pas pour autant interchangeables. Ce ne sont pas de synonymes. La redondance, c’est quelque chose qui est réalisé afin d’éviter les défaillances dans le système. C’est quelque chose de préventif, qui est mis en place pour éviter les défaillances. La résilience, étymologiquement, est liée au verbe « résoudre ». La résilience, c’est l’art de trouver des solutions une fois qu’un problème est survenu. La résilience est curative.
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisÉvolutivité horizontale (horizontal scaling)
Pour faire face à l’augmentation de la charge, deux options sont possibles : ajouter de nouveaux serveurs ou augmenter la capacité des serveurs utilisés. L’évolutivité horizontale fait référence à la première option, l’horizontalité verticale à la seconde.
L’évolutivité horizontale est la méthode utilisée pour construire des architectures cloud redondantes. Pour créer de la redondance, il faut en effet ajouter de nouveaux serveurs. Cela permet d’éliminer les points uniques de défaillance. Mais cela pose forcément la question de l’interconnexion entre les serveurs. La technique utilisée est celle de l’équilibrage de charge (load balancing en anglais). Elle consiste à répartir le trafic les différents serveurs (physiques ou virtuels). Mais le fait de n’utiliser qu’un seul répartisseur recrée un point unique de défaillance. Pour créer une architecture cloud redondante, il faut donc impérativement utiliser plusieurs répartisseurs de charge : au minimum deux. La configuration des répartisseurs est un vase sujet. Quelles règles de répartition utiliser ? On peut envisager une distribution du trafic en fonction du type de trafic, des contenus, des schémas de trafic ou de la capacité des serveurs de répondre aux requêtes. Les équilibreurs de charge permettent de gérer le trafic de manière logique. Comment le trafic est-il géré dans une couche physique ?
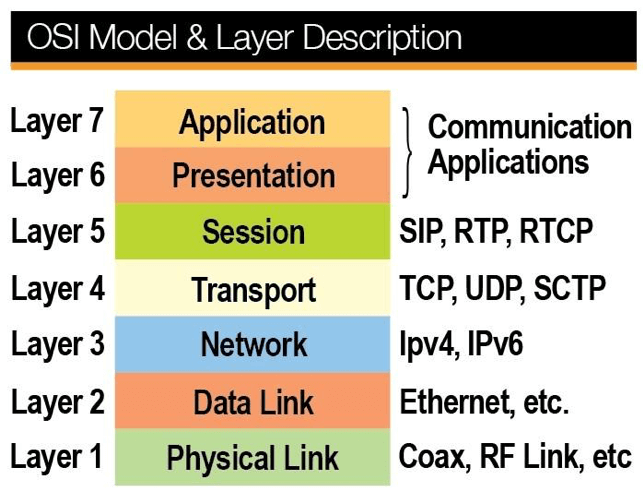
Le modèle OSI et la description des couches
Le modèle OSI est un outil très utile quand on travaille sur des architectures cloud complexes. Il s’agit d’un standard, d’un ensemble de normes décrivant la manière dont les serveurs doivent être connectés entre eux. Il repose sur une conception précise des différentes couches du système. La stack OSI commence toujours avec la couche physique, comme le montre le schéma ci-dessous. Elle est chargée de la transmission des informations entre les différents interlocuteurs. Aujourd’hui, la plupart des répartisseurs de charge travaillent à tous les niveaux de la stack OSI. Revenons à notre question initiale : comment les répartisseurs de charge sont connectés physiquement aux différents serveurs du système pour créer les chemins d’entrée et de sortie ? En général, cela suppose d’utiliser plusieurs commutateurs. Aujourd’hui, beaucoup d’équilibreurs de charge combine ensemble la densité de ports des commutateurs, la capacité de routage des routeurs et les fonctions logiques des répartisseurs de charge, le tout dans un dispositif unique simplifiant l’architecture et permettant de réduire les coûts.
La couche web et les couches d’application peuvent souvent être fondues dans le même serveur. Cela peut d’ailleurs poser des problèmes de sécurité. Si l’intégrité d’un serveur est menacée, les deux services peuvent potentiellement être touchés. C’est pour cette raison que la plupart des architectures cloud séparent ces deux couches.
Architectures logiques vs Architectures physiques
Une architecture peut être physique ou logique. Il importe de bien comprendre la différence entre les deux. Les diagrammes logiques montrent comment les éléments circulent dans le système. Pour se concentrer sur les flux logiques, on élimine des diagrammes certaines connexions physiques. A l’inverse, les couches physiques peuvent ne pas inclure certains détails logiques et certaines configurations pour se concentrer sur les caractéristiques et attributs physiques du design. Les schémas présentés dans l’article sont d’essence logique.
Les architectures avec mise à l’échelle automatique (autoscaling architecture)
L’un des principaux bénéfices du cloud computing réside dans sa capacité à aligner à chaque instant les ressources et les besoins en ressources. L’autoscalling ou mise à l’échelle automatique désigne la capacité d’augmenter la capacité de l’environnement dans le cloud de manière automatique en fonction de la variation des besoins des services & applications. La qualité de service reste la même quelle que soit le volume de ressources utilisé. L’autoscaling est très souvent utilisé par les applications et services web utilisant l’une des architectures cloud présentées plus haut. Dans le schéma ci-dessous, un nouveau serveur est ajouté dynamiquement suite à un dépassement de seuils.
L’autoscaling repose dans la majorité des cas sur les équilibreurs de charge. Ces derniers doivent être pré-configurés ou configurés de manière dynamique pour gérer les nouveaux serveurs ajoutés.
Les architectures cloud prennent de plus en plus de poids, nous le constatons tous les jours dans notre métier de consultant en Data Marketing. Quelque soit le système d’information que vous utilisez, il est important de s’intéresser à ces technologies. Nous espérons vous avoir aidé par ce quelques définitions à mieux comprendre quelques uns des concepts clés de cloud computing.
Laisser un commentaire