Aujourd’hui, la donnée est produite en continu par de multiples sources et circule entre de nombreux outils et applications. Dans de nombreux cas, la donnée produite ne peut être exploitée que si elle est traitée en temps réel.
Prenons l’exemple tout bête (mais emblématique) d’un abandon de panier sur un site e-commerce. Pour relancer l’internaute avec une offre personnalisée quelques minutes après qu’il ait quitté le site, l’information doit remonter en temps réel vers l’outil d’emailing avec les attributs permettant de personnaliser le message.
C’est justement là qu’intervient le Data Streaming. Cette approche consiste à considérer la donnée comme un flux continu (streaming) pouvant être diffusé et consommé en temps réel, plutôt que comme une série de batchs traités ponctuellement. Le streaming apporte la réactivité nécessaire aux cas d’usage marketing et CRM les plus avancés.
Qu’est-ce que le Data Streaming ?
Définition et caractéristiques clés
Le Data Streaming est une méthode de gestion et de transfert de données dans laquelle les données sont traitées en continu, au fur et à mesure de leur production. Contrairement au traitement par lots qui consiste à accumuler les données puis à les traiter par blocs, le streaming les voit comme un flux continu qui peut être consommé en temps réel par différents processus et applications.
Un système de Data Streaming présente les caractéristiques suivantes :
- Les données sont diffusées en continu par la source, sans début ni fin prédéfinis.
- Elles sont découpées en une série d’enregistrements de petite taille (quelques ko).
- Elles sont consommées par un ou plusieurs destinataires dès leur émission.
- Les traitements appliqués sont exécutés à la volée, sur chaque micro-batch.
- La latence est très faible (de l’ordre de la seconde ou de la milliseconde).
Le Data Streaming répond aux limites du traitement par lots dans les architectures data modernes. Le batch implique de la latence et des goulets d’étranglement puisqu’il faut attendre qu’un volume suffisant de données soit accumulé pour déclencher le traitement. Avec le streaming, les données deviennent exploitables dès leur création et peuvent alimenter les applications en continu, sans temps de latence.
Les 3 composantes clés d’une architecture de Data Streaming
Les architectures de Data Streaming sont organisées autour de trois composantes clés :
- Les sources de données qui génèrent les événements.
- Les consommateurs qui exploitent les données diffusées.
- Un système de messagerie qui sert de tampon et de point d’échange.

Les sources de données émettent les enregistrements de façon continue vers le broker. Celui-ci met en mémoire les événements dans une file d’attente et les distribue aux consommateurs au fur et à mesure, selon un modèle pub/sub (publication-souscription). Les données ne sont pas stockées de façon persistante mais conservées temporairement par le broker, le temps que tous les consommateurs les aient reçues.
Plusieurs motifs de traitement peuvent être appliqués aux flux de données :
- La transformation, qui applique des opérations (filtre, agrégation…) à chaque enregistrement sans modifier la structure du flux.
- L’enrichissement, qui ajoute des informations à chaque enregistrement en les combinant à des données de référence (catalogue produit, clients…)
- La corrélation, qui combine plusieurs flux pour calculer des métriques ou détecter des motifs.
- Le partitionnement, qui découpe le flux en sous-flux parallèles pour des questions d’isolation ou de scalabilité.
Ces traitements peuvent être enchaînés de façon flexible au sein d’un pipeline temps-réel, chaque composant souscrivant aux événements produits par le précédent. On parle d’architecture orientée événements : les données circulent en continu et déclenchent des actions dès leur consommation, sans latence.
Les principaux cas d’usage du Data Streaming
Le Data Streaming ouvre un large éventail d’opportunités pour les entreprises.
Voici un tour d’horizon des domaines dans lesquels le streaming fait la différence :
- L’analyse temps réel. Le Data Streaming permet de calculer des métriques et des indicateurs à la volée, au fil de l’eau, sans attendre la fin d’une période arbitraire. Dans le ecommerce, par exemple, il devient possible de suivre des KPIs comme le taux de conversion ou le panier moyen en temps réel et de réagir sans délai aux variations. Autre exemple dans le domaine de l’industrie, où le streaming de données permet de monitorer en continu des paramètres issus des capteurs (température, pression, vibrations…) et de prendre des décisions à la milliseconde.
- La détection d’anomalies. L’analyse des flux de données en continu permet de repérer des signaux faibles ou des patterns suspects qui seraient passés inaperçus avec du traitement batch. Et sur ce terrain, les cas d’usage sont nombreux : détection de fraude sur des transactions bancaires, repérage de failles de sécurité sur un réseau, identification de pannes sur une chaîne de production…Le streaming réduit les délais de réaction face aux incidents.
- Le marketing automation. En marketing automation, le Data Streaming est ce qui permet de mettre en oeuvre des cas d’usage nécessitant le temps réel.
- L’alimentation en données. Au-delà du déclenchement des actions, le Data Streaming permet aussi d’alimenter les applications en données fraîches. Des dashboards décisionnels aux apps mobiles en passant par les objets connectés, de plus en plus de services ont besoin d’un accès continu à une information à jour. Avec le streaming, ces applicatifs peuvent « consommer » les données en temps réel, sans synchronisation complexe.
- L’intégration de données. Lorsque des données de référence sont gérées dans plusieurs systèmes (CRM, ERP, MDM…), maintenir la cohérence de toutes les données est un vrai défi. C’est ici que le streaming de données entre en jeu, en permettant de diffuser chaque mise à jour à l’ensemble des applications. Exit les fastidieuses tâches de synchronisation.
Le dénominateur commun de tous ces cas d’usage ? Exploiter les données à chaud, dès leur création, sans attendre. Le streaming casse les silos entre applications et accélère la circulation de l’information. Il élimine les inefficiences des processus batchs.
Bien sûr, ces bénéfices ont un prix : une plus grande complexité architecturale et de nouveaux défis en termes de scalabilité, de résilience et de sécurité. Mais pour les organisations mûres sur la donnée, l’investissement en vaut largement la peine. Le Data Streaming leur permet de transformer leur relation à la donnée et d’en tirer une valeur business immédiate.
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisComment mettre en œuvre le Data Streaming ?
Pour tirer parti du Data Streaming, il faut comprendre les principes et les patterns d’architecture qui le sous-tendent. Cette section passe en revue les composants clés d’une architecture streaming et les bonnes pratiques de mise en œuvre.
Les briques d’une architecture streaming
Un système de Data Streaming s’appuie sur plusieurs composants logiciels dédiés :
- Un ou plusieurs brokers de messages qui servent de point d’échange entre les producteurs et les consommateurs de données. Les brokers les plus populaires sont Apache Kafka, Amazon Kinesis et Azure Event Hubs. Ils assurent la persistance temporaire des événements et leur distribution selon un modèle pub/sub.
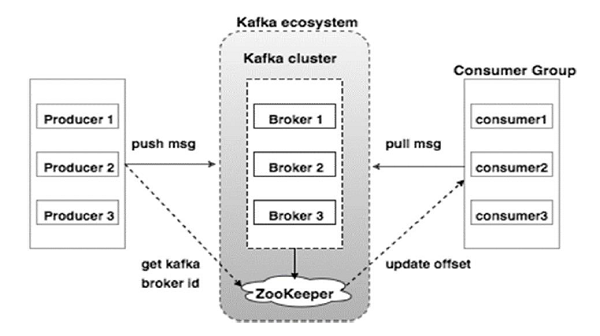
- Des connecteurs qui facilitent l’ingestion de données depuis les sources (bases de données, fichiers, APIs…) vers les brokers. La plupart des brokers proposent des connecteurs natifs pour les sources les plus courantes. Des frameworks d’ingestion comme Apache Nifi ou Streamsets peuvent également être utilisés.
- Des processeurs de flux qui appliquent des traitements aux événements diffusés par les brokers. Les plus connus sont Apache Spark Streaming, Apache Flink et Apache Storm. Ces outils proposent des APIs de haut niveau pour développer des jobs de streaming scalables et tolérants aux pannes.
- Des bases de données temps réel qui permettent de stocker et de requêter les données issues des flux. On peut citer Apache Druid, InfluxDB ou Elasticsearch. Ces services sont conçus pour l’ingestion à haute fréquence et les requêtes analytiques à faible latence.

Au-delà des outils, la mise en place d’une architecture streaming implique de repenser la façon de modéliser et de traiter la donnée. Les approches classiques de type « schema on write » laissent place à des modèles plus flexibles de type « schema on read« , dans lesquels la structure de la donnée est définie à la consommation plutôt qu’à la production.
Les bonnes pratiques de conception
La conception d’une architecture streaming répond à des principes spécifiques qui sont autant de bonnes pratiques à suivre.
En voici quelques-uns :
- Privilégier l’asynchronisme et le découplage. Dans une architecture streaming, les producteurs et les consommateurs de données sont découplés et communiquent de façon asynchrone via le broker. Ce découplage apporte de la flexibilité et de la robustesse : une panne ou un pic de charge d’un composant ne bloque pas tout le système.
- Traiter les événements comme des faits immuables. Chaque événement reçu est considéré comme un fait qui ne peut être modifié. Toute mise à jour est représentée par un nouvel événement. C’est ce principe qui garantit l’intégrité et la traçabilité des données dans le système.
- Penser « temps réel » de bout en bout. Pour tirer pleinement parti du streaming, il faut éviter les goulets d’étranglement et les ruptures dans le pipeline de données. Chaque composant doit donc être capable d’ingérer et de traiter les événements avec une faible latence, de l’ingestion à la consommation des données.
- Adopter une gestion fine des états. Contrairement au batch qui opère sur des données figées, le streaming traite des événements qui arrivent de façon continue. Maintenir un état cohérent dans ce contexte est un défi. Il faut mettre en place des stratégies de snapshotting et de réconciliation des états distribués.
- Prévoir les mécanismes de reprise sur erreur. Dans une architecture streaming, chaque composant peut tomber en panne indépendamment des autres. Pour garantir la fiabilité du système, il faut prévoir des mécanismes de reprise sur erreur, par exemple en rejouant les événements à partir d’un offset.
- Suivre les principes du « serverless ». L’approche serverless est particulièrement adaptée au streaming. Elle consiste à déporter les aspects infrastructure et scalabilité sur le cloud.
Les étapes d’un projet streaming
La mise en œuvre d’un projet de Data Streaming est un processus complexe qui implique de multiples dimensions : technique, organisationnelle et méthodologique. Voici les principales étapes à suivre pour mener à bien un projet Data Streaming.
#1 Définition des objectifs et des cas d’usage
Tout projet de streaming doit partir d’une vision claire des objectifs business :
- Quels sont les cas d’usage prioritaires ?
- Quels bénéfices en attendre ?
- À quelle échéance ?
Il est important d’impliquer les métiers dès cette phase pour comprendre leurs besoins et définir des cas d’usage à forte valeur ajoutée. Cette vision servira de boussole tout au long du projet.
#2 Cadrage de l’architecture cible
L’étape suivante consiste à dessiner les grandes lignes de l’architecture cible :
- Quelles seront les sources de données ?
- Quels composants logiciels (brokers, processeurs, bases de données…) ?
- Quelles intégrations avec le SI existant ?
- Quels volumes et quelles performances viser ?
Il faut privilégier une architecture modulaire, scalable et résiliente, alignée sur les standards du marché. Un POC technique peut être réalisé sur un périmètre réduit pour valider les choix.
Plus de 100 entreprises accompagnées sur leurs projets CRM et Data
Cartelis accompagne les entreprises (B2C & B2B, de la startup au grand groupe) dans le cadrage et le déploiement de Projets CRM Marketing et Data.

#3 Sélection des technologies
Une fois l’architecture cible définie, place au choix des briques techniques. Kafka s’est imposé comme la plateforme de facto pour le streaming, mais il existe de nombreuses options pour les couches d’ingestion, de traitement et de stockage. Le choix doit se faire en fonction des compétences internes, du niveau de support requis et des exigences de scalabilité et de performance. Les offres cloud peuvent être un bon point de départ pour gagner en agilité.
#4 Mise en place de la gouvernance des données
Le streaming ne dispense pas d’une gouvernance des données rigoureuse, bien au contraire ! Il faut définir les règles de gestion des données qui circuleront dans la plateforme : modèle de données, qualité, sécurité, cycle de vie…
Les rôles et responsabilités de chaque partie prenante (producteurs, consommateurs, opérateurs…) doivent également être clarifiés. Des outils de catalogage et de lignage des flux peuvent être mis en place pour garder le contrôle.
#5 Développement des producteurs et des consommateurs
Le cœur du projet consiste à développer les composants qui alimenteront et exploiteront la plateforme de streaming :
- Côté producteurs : il faut collecter et ingérer des données depuis les sources (bases SQL, NoSQL, fichiers, APIs…), avec les connecteurs adéquats. M
- Côté consommateurs : il faut développer des applications qui souscriront aux flux pour déclencher des actions, alimenter des tableaux de bord, mettre à jour des référentiels…
Si vous vous intéressez aux sujets data, ces articles pourraient aussi vous intéresser :
#6 Construction des pipelines de traitement
Entre producteurs et consommateurs s’intercalent souvent des traitements pour transformer, enrichir ou corréler les événements : filtrage, agrégation, jointure…
Ces traitements sont implémentés sous forme de jobs de streaming, avec des frameworks comme Spark Streaming ou Kafka Streams. Ils doivent être conçus de façon modulaire, testable et résiliente. Leur développement répond à des patterns spécifiques (event-driven, stateful…).
Discutons de votre projet
Besoin d'accompagnement à la conception et au déploiement de votre projet data ?
Prenons contact#7 Mise en place de la supervision et exploitation
Un projet de streaming ne s’arrête pas à la MEP. Une fois la plateforme opérationnelle, il faut en assurer la supervision et l’exploitation au quotidien.
Et cela passe par la mise en place d’outils de monitoring pour suivre les métriques clés (latence, débit, erreurs…), d’alerting pour réagir aux incidents et de capacity planning pour anticiper les montées en charge. Les mises à jour et l’ajout de nouvelles fonctionnalités doivent se faire de façon agile.
#8 Conduite du changement et évangélisation
Dernière étape clé : accompagner l’adoption de ce nouveau paradigme au sein de l’entreprise. Le streaming implique souvent un changement de culture et de méthodes de travail pour les équipes techniques et métiers. Il faut donc prévoir des actions de conduite du changement : formation, support, partage de bonnes pratiques…et surtout communiquer régulièrement sur les bénéfices obtenus pour créer une dynamique vertueuse.
Vous avez un projet Data Streaming ? Entrons en contact
La mise en place d’une architecture Data Streaming est un véritable projet d’entreprise qui nécessite une solide expertise technique et méthodologique.
Notre équipe vous accompagne à chaque étape, du cadrage stratégique au déploiement opérationnel, en passant par le choix des technologies et la conduite du changement. Forts de nombreuses missions de ce type menées dans des secteurs variés, nous saurons vous guider pour faire les bons choix et concrétiser rapidement la valeur de vos données.
Vous avez un projet data ? Prenons contact pour un premier échange sans engagement. Nous serons ravis de partager notre expérience et de comprendre votre contexte.
Laisser un commentaire