Un temps éclipsés par le métier supposément plus sexy de Data Scientist, les Data Engineers sont revenus sur le devant de la scène et représentent aujourd’hui les profils data les plus recherchés sur le marché. Leur mission principale ? Gérer des infrastructures data. Ce sont eux, notamment, qui s’occupent de mettre en place et de maintenir les flux de données entre votre base de données clients et vos différences sources de données. Dans un univers marqué par le rôle croissant de la data, la multiplication des outils et des interconnections entre les systèmes, le Data Engineer devient une pièce maîtresse.
On vous explique tout ce qu’il faut savoir sur ce métier passionnant. On va parler missions, compétences, salaires et formations.
Sommaire
- L’essentiel à retenir sur le métier de Data Engineer
- Un Data Engineer, c’est quoi ? [Définition]
- Les 5 principales missions d’un Data Engineer
- Les 7 compétences clés d’un Data Engineer
- Le salaire d’un Data Engineer – entre 45k€ et 100k€+ par an
- La formation d’un Data Engineer
- Les réponses à vos questions au sujet des Data Engineers
L’essentiel à retenir sur le métier de Data Engineer
- Le Data Engineer gère les données et conçoit, développe et maintient les infrastructures nécessaires au traitement des données. En amont du travail des Data Scientists, les Data Engineers garantissent l’intégrité, l’évolutivité et la sécurité des données, créant ainsi des plateformes capables de traiter de vastes volumes de données dans des conditions optimales.
- Si les Data Engineers partagent certains domaines d’expertise avec les Data Analysts et les Data Scientists, leurs rôles et compétences sont distincts. Les Data Engineer veillent à la qualité des données en amont et consolident les données en mettant en place des processus de contrôle qualité pour assurer la cohérence et l’intégrité des données.
- Pour devenir un Data Engineer compétent, il est essentiel de développer un ensemble de compétences techniques : Python, Java, Scala et SQL, ainsi que des concepts de bases de données relationnelles et NoSQL.
- Les salaires des Data Engineers varient en fonction de l’expérience, du secteur d’activité et des compétences spécifiques. En général, le salaire moyen se situe entre 45 000 € et 100 000 €+ par an. Les formations pour devenir Data Engineer comprennent soit des cursus en école d’ingénieur, soit des spécialisations en analyse de données, ou bien encore des masters en Data Science ou en Intelligence Artificielle.
Un Data Engineer, c’est quoi ? [Définition]
Définition du Data Engineer
Le Data Engineer est un professionnel chargé de concevoir, développer et maintenir les infrastructures de données. Il assure ainsi la gestion fluide et sécurisée des données pour les analyses et les applications. Son travail se situe en amont de celui du Data Scientist, et son objectif principal est de concevoir des plateformes capables de traiter de vastes volumes de données dans des conditions optimales.
Il est chargé de mettre en place des pipelines de données sécurisés qui serviront aux Data Analysts et aux Data Scientists. Il possède une expertise étendue en langages de programmation tels que Scala et Python, largement utilisés dans le développement logiciel ainsi que les bases de données SQL et NoSQL et les technologies de traitement de données en temps réel, notamment Hadoop, Spark, Kafka, Flink et Storm.
Data Engineer Vs Data Analyst Vs Data Scientist
Data Engineer, Data Analyst et Data Scientist : trois métiers différents dans le domaine de la Data, mais chacun avec des compétences spécifiques.
- Comme on l’a dit, les Data Engineers sont responsables de la conception et de la construction de l’infrastructure de données qui permet de traiter et d’analyser les données de manière efficace. Ils construisent et entretiennent les pipelines de données, assurant le flux régulier des données depuis les différentes sources jusqu’aux systèmes de stockage des données. En bref, ils garantissent un rôle essentiel par rapport à l’intégrité, l’évolutivité et la sécurité des données.
- Les Data Analysts, de son côté, s’occupent plutôt de la visualisation des données et de l’analyse statistique en élaborant des rapports, des graphiques, des diagrammes et des tableaux de bord interactifs qui facilitent la compréhension des tendances, des schémas et des relations présentes dans les données pour communiquer efficacement les résultats clés. Leur rôle est crucial pour transformer les données brutes en informations exploitables qui stimulent la croissance de l’entreprise et optimisent les opérations. Ils utilisent des méthodes telles que l’analyse descriptive, l’analyse exploratoire et l’analyse prédictive pour extraire des informations précieuses et ils appliquent des modèles et des algorithmes avancés pour détecter les corrélations, les anomalies et les tendances significatives.
- Enfin, les Data Scientists s’occupent surtout de l’extraction de connaissances et d’informations à partir d’ensembles de données complexes et volumineux en utilisant des techniques analytiques avancées. Ils ont recours au machine learning et à des langages de programmation comme Python ou R. Leur mission consiste surtout à créer des modèles, développer des algorithmes et exploiter des techniques telles que la modélisation prédictive et l’exploration de données pour résoudre des problèmes complexes liés aux données. Les Data Scientists s’efforcent d’identifier des modèles, de faire des prédictions et de fournir des recommandations fondées sur des données qui contribuent à l’innovation et à la prise de décisions stratégiques.
Si ces métiers se ressemblent fortement, leurs objectifs principaux et leurs domaines d’expertise sont tout de même grandement différent : et surtout, ils ne sont pas interchangeables. Pour en savoir plus, consultez notre article consacré aux différences entre Data Scientist et Data Engineer !
Les 5 principales missions d’un Data Engineer
Comme on l’a compris, le Data Engineer est responsable de la construction et de la maintenance des systèmes et des architectures qui permettent aux entreprises de traiter efficacement les données ! Il a 5 principales missions à remplir :
#1 Concevoir l’architecture infra pour valoriser les données
Un Data Engineer doit concevoir l’architecture globale, (par exemple, un data lake) ou locale avec une utilisation spécifiques émanant de directions métiers précises. Dans ce contexte, le Data Engineer doit définir et valider les choix architecturaux relatifs aux solutions Data à adopter.
#2 Veiller à la qualité des données
Le Data Engineer doit effectuer toutes les tâches en amont nécessaires pour fournir des données « propres » aux Data scientists. En effet, les Data scientists ont besoin de données de qualité pour mener à bien leurs tâches car les algorithmes de machine learning sont très sensibles aux valeurs manquantes, aux écarts (outliers) et à la cohérence de la structure interne des données.
#3 Normaliser et consolider les données
Un Data Engineer doit mettre en place des processus de contrôle qualité pour vérifier la cohérence, l’intégrité et la validité des données ! Cela inclut les process’ de détection et la correction des erreurs, l’élimination des doublons, la gestion des valeurs manquantes et la surveillance régulière de la qualité des données.
#4 Automatiser les tâches récurrentes
Étant donné que l’extraction, le nettoyage et la transformation des données peuvent être chronophages, un Data Engineer doit automatiser autant que possible ces tâches par des outils et des workflows, tel qu’Apache.
#5 Analyses décisionnelles sur les données traitées
Un Data Engineer doit effectuer des croisements de données et des travaux de consolidation afin de générer des rapports qui soutiennent la prise de décision (tableaux de bord, KPI) en utilisant différentes technologies, en fonction du patrimoine IT de l’entreprise.
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisLes 7 compétences clés d’un Data Engineer
Un Data Engineer possède un ensemble de compétences techniques et analytiques pour gérer, transformer et analyser de grandes quantités de données :
#1 Connaissance des langages de programmation
Python, Java, Scala, SQL, ou des langages spécialisés comme R… Ces langages sont utilisés pour développer des scripts, des pipelines de données et des requêtes de manipulation de données.
#2 Compréhension des concepts de bases de données
Un Data Engineer doit connaître les bases de données relationnelles (comme MySQL, PostgreSQL) et les bases de données NoSQL (comme MongoDB, Cassandra). Cela inclut la modélisation des données, les requêtes SQL, les indexation, la normalisation et la dénormalisation.
#3 Expérience en ingénierie de données
La collecte, le nettoyage, la transformation et l’intégration des données, tout cela nécessite de savoir utiliser des outils et des frameworks tels que Apache Spark, Apache Kafka, Apache Airflow ou des solutions de streaming comme Apache Flink.
#4 Compétences en infrastructure et technologies de Big Data
Un Data Engineer doit connaître Hadoop, Apache HBase, Apache Hive, Apache HDFS et d’autres systèmes distribués. Il est également important d’avoir une compréhension des concepts de cloud computing et de savoir travailler avec des services de cloud tels que Amazon Web Services (AWS), Microsoft Azure ou Google Cloud Platform (GCP).
#5 Compétences en gestion de projet
Moins techniques mais tout aussi essentielles pour travailler en groupe, un Data Engineer doit avoir de bonnes capacités relationnelles pour collaborer efficacement avec d’autres membres de l’équipe, à communiquer clairement et à résoudre les problèmes est donc essentielle.
#6 Compréhension des concepts de sécurité des données
Pour sécuriser les données, un Data Engineer doit maîtriser chiffrement, les contrôles d’accès, l’anonymisation des données et la conformité aux réglementations telles que le RGPD.
#7 Capacité à apprendre et à s’adapter rapidement
L’émergence de nouvelles technologies et de nouvelles pratiques oblige le Data Engineer à apprendre rapidement de nouvelles compétences et de s’adapter à ces changements pour rester à jour dans son domaine.
Le salaire d’un Data Engineer – entre 45k€ et 100k€+ par an
Le salaire d’un Data Engineer varie en fonction du niveau d’expérience, du secteur d’activité, des compétences spécifiques et du secteur géographique. En général, un Data Engineer débutant peut s’attendre à un salaire d’environ 45 000 € par an. Avec l’acquisition d’une expérience professionnelle, la moyenne nationale se situe autour de 60 000 € par an.
Le niveau d’expérience joue aussi un rôle déterminant dans la rémunération d’un Data Engineer ! Les professionnels avec au moins de deux ans d’expérience peuvent gagner entre 50 000 € et 70 000 € par an et à mesure que l’expérience augmente, les salaires peuvent atteindre entre 70 000 € et 90 000 € par an pour les Data Engineers avec une expérience de 5 à 10 ans. Les Data Engineers expérimentés (10 ans d’expérience ou plus) peuvent prétendre à des salaires de plus de 100 000 € par an.
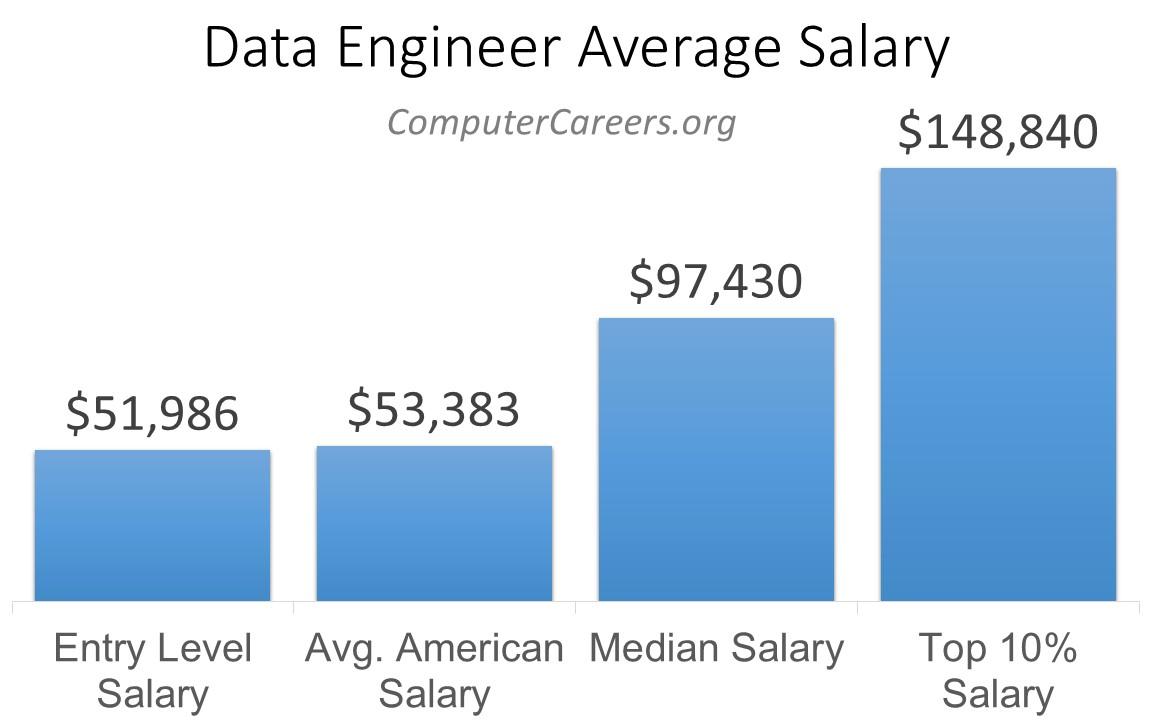
Le secteur d’activité est également déterminant déterminant : les industries technologiques et financières ont tendance à offrir des salaires plus élevés en raison de la forte demande de professionnels spécialisés dans la gestion des données. Les secteurs du commerce électronique, des start-ups et de l’intelligence artificielle peuvent également proposer des salaires compétitifs.
Pour finir, les avantages complémentaires (bonus, stock-options, avantages sociaux, opportunités d’avancement) sont à prendre en compte dans la rémunération globale d’un Data Engineer. Evidemment, ces avantages peuvent varier d’une entreprise à l’autre et d’un secteur d’activité à l’autre.
La formation d’un Data Engineer
Le métier de Data Engineer est très récent ! Les formations universitaires sont donc peu nombreuses pour se spécialiser mais un cursus dans une bonne école d’ingénieur vous facilitera la tâche par la suite. Vous pouvez donc suivre une école d’ingénieur : Telecom Paris, Epitech, Ingésup, Polytech, IMT Mines. Vous pouvez aussi suivre une spécialisation en analyse de données à l’Essec ou l’EM Grenoble.
Suivre un cursus en école d’informatique avec une spécialité en Exploration des données et Décisionnel, ou de poursuivre un master spécialisé en Data Science ou en Intelligence Artificielle est égaleent une alternative ! En effet, de nombreuses écoles spécialisées dans le domaine des données émergent, comme l’École de la Data fondée en 2019 et d’obtenir la certification de « Data Engineer ».
Les certifications spécifiques dans le domaine de la gestion des données peuvent également un gros plus : les certifications liées à des technologies telles qu’Apache Hadoop, Apache Spark ou AWS Certified Big Data – Specialty peuvent être valorisées par les employeurs et entraîner une augmentation de salaire.
De plus en plus d’entreprises (Facebook, Airbnb) proposent des programmes internes appelés « Data Camps » ou « Data University » : ces initiatives visent à former les employés en interne sur tous les aspects liés aux données, afin de sensibiliser l’ensemble de l’entreprise à ce domaine. En effet, l’enjeu de la sécurité des données est crucial pour ces entreprises.
Si vous souhaitez compléter votre cursus, vous pouvez vous tourner des ressources en ligne telles que le cours « Data Science, Deep Learning, & Machine Learning with Python » sur Udemy, qui couvre les principes de l’analyse de données, de la science des données, des statistiques et du machine learning. Des plateformes comme FreeCodeCamp et Hackernoon publient régulièrement des articles et des tutoriels sur divers sujets liés à la Data Science et au développement, offrant ainsi des opportunités d’apprentissage supplémentaires. Pour finir, nous conseillons également de lire l’ouvrage « Data Science For Business » qui explique le succès de certains modèles ! Un must-have en la matière.
Les réponses à vos questions au sujet des Data Engineers
Qu’est-ce qu’un Data Engineer ?
C’est un professionnel spécialisé dans la gestion et l’ingénierie des données : responsable de la collecte, du nettoyage, de la transformation et du stockage des données, il les rend utilisables pour l’analyse et la modélisation.
Quelles sont les compétences nécessaires pour devenir un Data Engineer ?
Un Data Engineer doit maîtriser des langages de programmation (Python, SQL) mais aussi avoir une connaissance des bases de données, une expertise en ingénierie de données, une compréhension des technologies Big Data, des compétences en gestion de projet et une capacité à apprendre rapidement.
Quelle est la différence entre un Data Engineer et un Data Scientist ?
Si les Data Scientists analysent et interprètent des données pour obtenir des informations et des connaissances, les Data Engineers se concentrent plus surla préparation et l’ingénierie des données pour les rendre utilisables.
Quels outils et technologies les Data Engineers utilisent-ils ?
Les Data Engineers utilisent une variété d’outils et de technologies tels que Apache Hadoop, Apache Spark, SQL, NoSQL, Python, Java, Apache Kafka, Apache Airflow, ainsi que des services de cloud computing tels que AWS, Azure et GCP.
Quelles sont les principales missions d’un Data Engineer ?
Un Data Engineer collecte, nettoie et prépare des données, puis conçoit l’infrastructure de stockage, crée les pipelines de données et la maintenance des systèmes de données.
Comment un Data Engineer assure-t-il la sécurité des données ?
Pour garantir la sécurité des données, un Data Enginner doit mettre en place des mécanismes de contrôle d’accès, en chiffrant les données sensibles, en surveillant les activités suspectes, en appliquant des pratiques de sécurité recommandées et en vous conformant aux réglementations en matière de protection des données.
Quelles sont les tendances émergentes dans le domaine du Data Engineering ?
Les tendances émergentes porte sur l’adoption croissante du cloud computing, l’utilisation de l’intelligence artificielle et de l’apprentissage automatique pour automatiser les tâches de gestion des données, ainsi que l’intégration de l’analyse en temps réel pour des prises de décision plus rapides.
Qu’est-ce qu’un ETL et pourquoi est-il important pour un Data Engineer ?
ETL (Extract, Transform, Load) est un processus essentiel dans l’ingénierie des données. Il consiste à extraire les données à partir de différentes sources, à les transformer pour les rendre conformes aux besoins d’analyse et de modélisation, puis à les charger dans un système de stockage ou un entrepôt de données. L’ETL est important car il permet de préparer les données en les nettoyant, en les normalisant et en les agrégeant.
Qu’est-ce qu’un data pipeline et quel est son rôle dans l’ingénierie des données ?
Un data pipeline est un flux d’opérations qui orchestre le mouvement des données de leur source d’origine vers leur destination finale. Le rôle principal d’un data pipeline est d’automatiser le flux des données, en veillant à ce qu’elles soient traitées de manière fiable, efficace et cohérente.
Cartelis - Template - Liste prestataires Data en France
Download
Laisser un commentaire