Vous réfléchissez à mettre en place un Data Warehouse pour mieux organiser vos données ? Cet article synthétique va vous aider à faire avancer votre réflexion.
Le paysage des Data Warehouses s’est beaucoup enrichi ces dernières années. Pour choisir la bonne technologie, vous devez avoir à la fois une bonne compréhension de vos besoins et une connaissance des différents types de solutions envisageables.
La distinction Data Warehouse Cloud Vs On Premise est l’une des plus structurantes, mais ce n’est pas la seule comme nous le verrons. Le choix de la technologie Datawarehouse dépend aussi de votre budget, du volume de données, du modèle de scalabilité, etc.
Nous allons étudier de près les principaux facteurs à prendre en compte dans le choix de votre Data Warehouse.
Sommaire
L’essentiel à retenir pour choisir son Data Warehouse
- Un Data Warehouse est un système de stockage et d’intégration de données qui permet aux entreprises de collecter, organiser et analyser des données provenant de différentes sources. Il fournit une vue globale des données, facilitant ainsi l’analyse et la prise de décisions stratégiques.
- Un Data Warehouse est essentiel pour les entreprises cherchant à exploiter efficacement leurs données pour améliorer leur prise de décision et leur compétitivité. Il consolide les données disparates en un seul endroit, ce qui facilite l’analyse, la création de rapports et la génération d’informations précieuses pour les équipes métier.
- Les critères clés pour faire le bon choix de de Data Warehouse sont le mode de distribution, les performances, la scalabilité, le coût et le temps de déploiement, le coût d’exploitation et de maintenance, et le support client.
Qu’est-ce qu’un Data Warehouse ?
Définition
Pour ceux qui ne sont pas au courant, voici une définition simple par Segment. Vous pouvez considérer un Data Warehouse comme un endroit où toutes vos données résident. Les entreprises utilisent un Data Warehouse pour agréger des données provenant de différentes sources afin de faciliter leur analyse.
Un Data Warehouse dans le cloud, comme vous pouvez l’imaginer, est un Data Warehouse qui existe entièrement en ligne. Contrairement aux Data Warehouses physiques, sur site, les Data Warehouses basés sur le cloud n’ont pas besoin de matériel physique, sont beaucoup plus faciles à mettre en œuvre et à dimensionner, et sont généralement moins chers que les Data Warehouses sur site. 
A partir de quand envisager d’utiliser un Data Warehouse?
Avec un Data Warehouse, vous bénéficiez d’une flexibilité ultime pour stocker et interroger ultérieurement vos données. Cela vous aide à répondre à ces questions analytiques difficiles que votre conseil d’administration peut poser et qui ne peuvent pas être résolues avec votre outil d’analyse standard.
Par exemple, Google Analytics peut vous donner une bonne idée des actions que les clients effectuent sur votre site web ou votre application. Cependant, vous êtes limité à poser des questions qui peuvent être répondues avec le nombre de variables, de propriétés et de types de graphiques qu’il fournit.
Les rapports et analyses que vous exécutez dans les Data Warehouses peuvent inclure des éléments de chacune des sources de données que vous combinez. C’est assez puissant ! Vous pouvez analyser les données de votre site web et de votre application, ainsi que d’autres plateformes que vous pourriez utiliser comme Salesforce, Zendesk, Stripe, et autres. Lorsque vous avez toutes vos données au même endroit, vous pouvez facilement exécuter des requêtes directement dans votre Data Warehouse ou via un outil BI comme Tableau, Looker Studio, ou Mode (consultez la section suivante pour en savoir plus sur ces outils).
Vous devriez envisager un Data Warehouse si vous souhaitez :
- Stocker de manière centralisée toutes vos données critiques pour l’entreprise.
- Analyser ensemble sur un seul emplacement vos données web, mobiles, CRM et d’autres applications.
- Approfondir davantage que les outils d’analyse traditionnels en interrogeant les données brutes avec SQL.
- Permettre à plusieurs personnes d’accéder simultanément au même ensemble de données.
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisLes critères à prendre en compte pour choisir son Data Warehouse
Choisir le bon Data Warehouse est essentiel pour une stratégie de Data Marketing réussie car un bon Data Warehouse offre une flexibilité d’analyse inégalée, consolide les données pertinentes et permet des décisions éclairées, ce qui conduit à des campagnes marketing plus impactantes. Une réflexion approfondie assure donc une base solide pour le succès du Data Marketing. Pour bien choisir son Data Warehouse, voici les critères les plus importants.
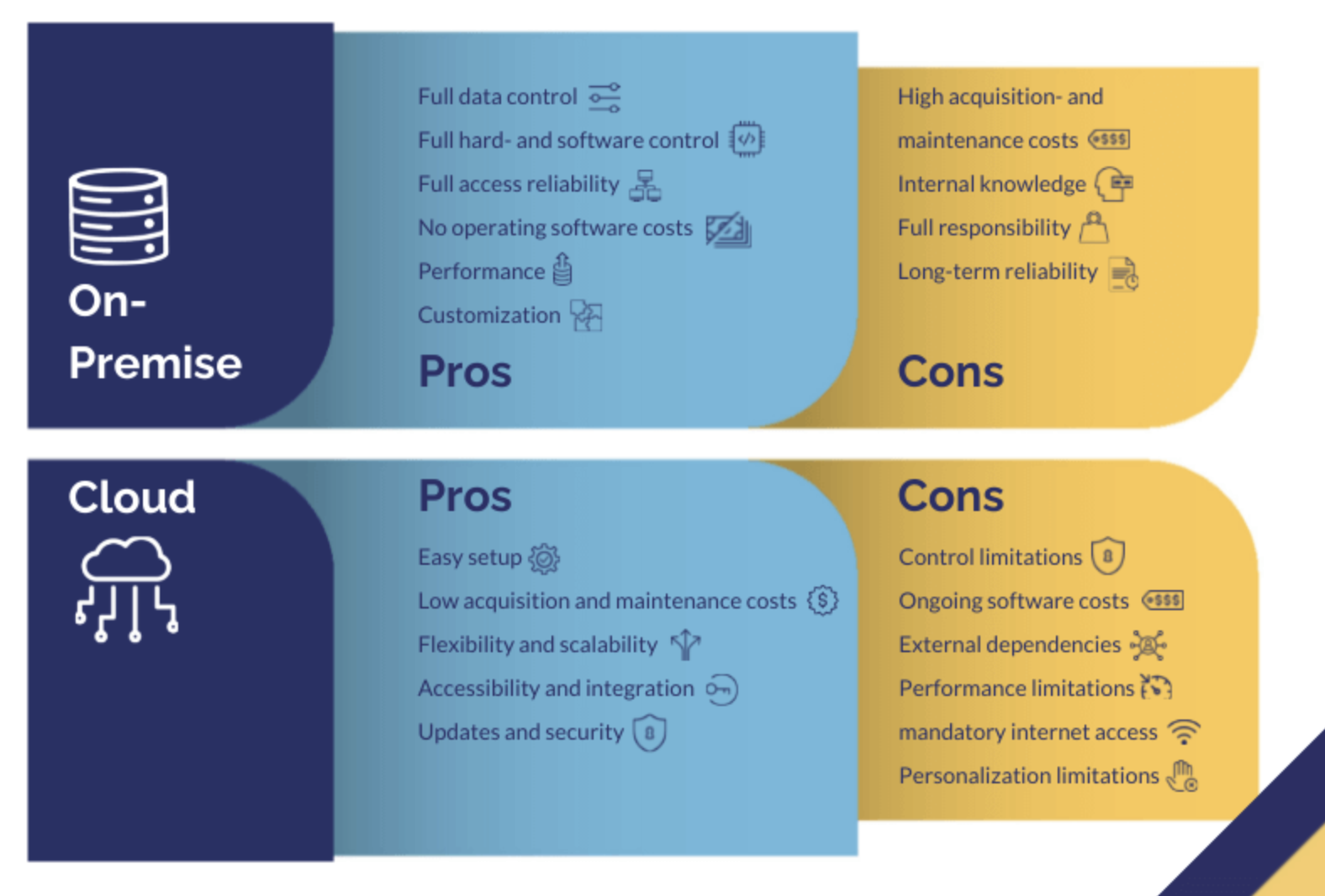
Le mode de distribution : Cloud ou On-Premise
La question que vous devez vous poser est la suivante : avez-vous des ressources suffisantes en interne pour vous occuper de la maintenance de votre entrepôt de données, pour gérer le support et les bugs ? Ce point est essentiel à prendre en compte dans votre choix. Si vous êtes une entreprise avec une grosse DSI, ce n’est pas la même chose que si vous êtes une startup…
Grosso modo :
- Si vous avez des ressources humaines en interne vous permettant d’assurer vous-même la maintenance du système, vous avez plus de choix. Vous avez par exemple la possibilité de créer votre propre (Big) Data Warehouse basé sur des frameworks comme Hadoop ou Greeplum. Ces systèmes requièrent un important travail de setup et de maintenance, ainsi que des personnes compétentes pour gérer le tout.
- Si vous n’avez pas les compétences en interne pour gérer la maintenance, vos possibilités sont plus limitées. Si vous êtes dans ce cas, nous vous conseillons de vous tourner vers les solutions modernes de Data Warehouse comme Redshift, BigQuery ou Snowflake. Que vous soyez administrateur ou utilisateur, vous n’avez pas besoin de vous soucier du déploiement, de l’hébergement, du redimensionnement des machines virtuelles, de la gestion des réplications et du cryptage. Vous pourrez commencer à utiliser votre entrepôt de données en utilisant des commandes SQL.
Les performances
La prochaine chose à considérer est la rapidité avec laquelle vous aurez besoin de vos données. Cela dépendra de la vitesse à laquelle vos requêtes peuvent s’exécuter et de la façon dont vous maintenez cette rapidité en période de forte demande. Comme vous pouvez l’imaginer, la performance et l’échelle sont étroitement liées. La performance augmentera à mesure que vous augmentez la taille de votre entrepôt de données ou que vous ajoutez manuellement des nœuds supplémentaires (par exemple, Amazon Redshift).
Bien que les analyses en temps réel soient essentielles pour certains cas d’utilisation, la plupart des analyses ne nécessitent pas de données en temps réel ou d’informations immédiates. Lorsque vous répondez à des questions telles que « qu’est-ce qui entraîne la perte d’utilisateurs ? » ou « comment les gens passent de notre application à notre site web ? », accéder à vos données avec un léger décalage est acceptable. Vos données ne changent pas autant d’une minute à l’autre et votre capacité à suivre les tendances plus importantes ne sera pas affectée. Un exemple d’organisation de Data Warehouse qui permet d’optimiser la performance est la modélisation en étoile, sur lequel nous faisons un zoom dans cet article.
La scalabilité
La prochaine considération concerne la quantité de données auxquelles vous accédez et l’échelle de données que votre Data Warehouse doit prendre en charge. Les entrepôts de données relationnels dans le cloud sont généralement capables de stocker des quantités massives de données sans trop de surcoûts. Vous n’aurez probablement pas besoin de plus que ce qu’ils proposent, surtout si l’analyse est l’utilisation principale.
Cependant, dans les cas où une échelle extrême est nécessaire (supérieure à 2 téraoctets de données), un Data Warehouse non relationnel sera généralement plus adapté car il ne contraint pas les données entrantes, ce qui permet d’écrire plus rapidement. Vous devrez également prendre en compte la manière dont un Data Warehouse spécifique s’adapte en période de demande.
Par exemple, Redshift peut prendre en charge d’énormes quantités de données, mais vous devrez ajouter manuellement plus de nœuds (pour augmenter le stockage et la puissance de calcul). En revanche, Snowflake propose une fonction d’auto-évolutivité qui crée et désactive dynamiquement des clusters selon les besoins.
Le coût et le temps de déploiement
On dit que le diable se cache dans les détails, et cela est doublement vrai lorsqu’il s’agit de la mise en œuvre d’un Data Warehouse. Voici quelques points importants à prendre en compte.
Lorsque vous choisissez entre les outils pour Data Warehouse, l’argent est souvent un facteur déterminant.
Malheureusement, calculer la différence de prix entre plusieurs plates-formes de Data Warehouses peut être compliqué. Les fournisseurs utilisent des approches radicalement différentes pour calculer le coût d’une configuration spécifique de puissance de calcul, de stockage, etc.
Ainsi, tout en consultant les informations tarifaires publiées par chaque fournisseur sur leur site web, renseignez-vous auprès de personnes de votre réseau sur le montant qu’ils ont payé pour des configurations similaires à celle dont vous aurez besoin.
En parlant de coûts, l’autre dépense à prendre en compte est celle liée aux ressources humaines. Par exemple, pouvez-vous gérer toute la mise en œuvre avec votre effectif actuel ou devrez-vous embaucher ou faire appel à un consultant pour gérer le projet ?
Le coût ne proviendra peut-être pas du même poste budgétaire que votre entrepôt, mais il est certainement lié. Le coût compte, mais le temps est souvent encore plus important, surtout pour les startups qui cherchent à avancer rapidement.
Si un Data Warehouse coûte légèrement moins cher qu’un autre mais prend cinq mois de plus à mettre en œuvre, cela représente cinq mois sans obtenir les informations dont votre entreprise a besoin pour surpasser la concurrence. Enfin, lorsque vous évaluez le temps de mise en œuvre, n’oubliez pas de prendre en compte le coût d’opportunité !
Si vous avez un projet relatif aux outils et à l’architecture CRM, ces articles pourraient aussi vous intéresser :
Le coût d’exploitation et de maintenance
Une fois votre Data Warehouse choisi et implémenté, il reste encore différents facteurs à prendre en compte. Plus votre équipe est réduite, plus il est probable que vos ingénieurs se concentrent sur la création de produits plutôt que de s’inquiéter des pipelines ETL et de la gestion quotidienne de votre Data Warehouse. Pour les Data Warehouse qui ne s’optimisent pas automatiquement, vous devrez faire en sorte qu’une personne passe du temps à effectuer des tâches de nettoyage, de redimensionnement et de surveillance du cluster pour garantir des performances optimales.
Cependant, la maintenance manuelle d’un Data Warehouse vous permet d’optimiser précisément celui-ci en fonction des besoins de votre entreprise. Plus vous consacrez de temps à l’ajustement manuel et à l’évolutivité de votre entrepôt de données, plus vous avez de contrôle sur les performances et les coûts. Pour un administrateur expérimenté d’entrepôt, « plus de maintenance » signifie plus de flexibilité et de contrôle. 
Le support client
Lorsque vous rencontrez des problèmes avec votre Data Warehouse, à quel point est-il probable que vous obteniez l’aide dont vous avez besoin au moment où vous en avez besoin ? Bien que personne ne choisisse un Data Warehouse uniquement en fonction du support qu’il peut obtenir, si deux systèmes d’entrepôt de données sont pratiquement équivalents, cela pourrait être le facteur décisif.
Lors de l’évaluation d’un outil, prenez le temps de vérifier la communauté d’assistance en ligne pour voir quel type d’aide vous pouvez attendre. Renseignez-vous également sur la disponibilité d’une assistance en direct que vous pouvez contacter… et si elle est incluse dans votre niveau de tarification. Vous pourriez être à l’aise avec l’idée d’utiliser la documentation pour gérer la plupart de vos problèmes d’assistance, mais avoir une personne réelle au bout du fil peut être un véritable atout en cas de besoin urgent.
Si vous vous intéressez aux sujets data, ces articles pourraient aussi vous intéresser :
Les réponses à vos questions sur les Data Warehouses
Pourquoi choisir un Data Warehouse dans le cloud plutôt qu’un entrepôt sur site ?
Un Data Warehouse dans le cloud offre une mise en œuvre rapide, une évolutivité automatique, et des économies sur les coûts matériels et opérationnels. Il permet également un accès à distance aux données et des mesures de sécurité avancées fournies par les fournisseurs de cloud.
Quels sont les facteurs clés à considérer lors du choix d’un Data Warehouse ?
Lors du choix d’un Data Warehouse, il est essentiel d’évaluer les performances, la scalabilité, la convivialité, la compatibilité avec les outils existants, les coûts, et le support client offert par les fournisseurs. Il est important de prendre en compte les besoins spécifiques de votre entreprise et d’opter pour une solution qui répond le mieux à vos exigences.
Quels avantages les Data Warehouse relationnels offrent-ils par rapport aux entrepôts de données non relationnels ?
Les Data Warehouse relationnels sont adaptés aux données structurées et permettent des requêtes SQL complexes, offrant une grande flexibilité dans la manipulation des données. En revanche, les Data Warehouses non relationnels sont conçus pour gérer des données semi-structurées ou non structurées et offrent une évolutivité horizontale pour traiter de grands volumes de données. Le choix dépendra du type de données et des besoins d’analyse de votre entreprise.
Comment assurer la sécurité et la conformité des données dans un Data Warehouse ?
La sécurité des données est primordiale pour un entrepôt de données. Optez pour des solutions de cloud sécurisées, utilisez le chiffrement pour protéger les données en transit et au repos, définissez des politiques d’accès et d’authentification strictes et surveillez régulièrement les activités suspectes. Assurez-vous également que votre entrepôt de données est conforme aux réglementations en vigueur concernant la protection des données.
Quelle est la différence entre un Data Warehouse relationnel et un Data Warehouse non relationnel ?
Les Data Warehouses relationnels sont basés sur des bases de données SQL traditionnelles et sont adaptés aux données structurées avec des relations complexes entre les tables. Les Data Warehouses non relationnels, également appelés entrepôts de données NoSQL, sont conçus pour gérer des données semi-structurées ou non structurées et offrent une évolutivité horizontale pour gérer de grandes quantités de données. Le choix dépend de la nature de vos données et de vos besoins d’analyse. 
Bonjour, j’eespère que vous allez bien.
Nous souhaitons utiliser SQL Server afin de créer un data warehouse pour la centralisation de l’ensemble de nos données provenant de plusieurs sources (MySQL, Oracle, fichiers …)
Nous avons deux types de serveurs et nous ne savons pas lequel utilisé.
serveur 1 : 5 cœurs, avec une fréquence 256 Mhz
serveur 2 : 2 cœurs, avec une fréquence 1000 Mhz
Nous aimerions savoir :
– Lequel des deux serveurs matériels opterons-nous et pourquoi ?
– Quel type de serveur souhaiterions-nous installer et pourquoi ?