La connaissance client et la personnalisation des actions de marketing-ventes reposent sur une infrastructure data claire et efficiente. C’est là qu’intervient le Data Engineering, l’ingénierie de données. Le but d’une projet data ? Construire ou optimiser l’infrastructure data de l’entreprise pour la mettre au service des équipes et des objectifs métiers.
Comment s’y prendre pour mener à bien son projet data ? C’est le sujet de cet article. Au programme : des conseils et des bonnes pratiques. On vous partage nos convictions et la méthodologie que nous pratiquons dans le cadre de nos accompagnements.
Discutons de votre projet
Besoin d'accompagnement à la conception et au déploiement de votre projet data ?
Prenons contactSommaire
Les 3 clés de réussite d’un Projet Data
1 – Bien cadrer les objectifs et les besoins métiers
Un projet data répond à des enjeux métiers et business. Il s’agit de mettre en place ou d’améliorer son infrastructure data afin de maximiser l’utilisation des données.
Certains pourraient se demander : Pourquoi disposer d’une infrastructure de données efficace ? La finalité, ce n’est pas l’infrastructure, c’est ce qui va être possible de faire grâce à elle. Une infrastructure de données répond à 3 familles de besoins :
- La connaissance client.
- La personnalisation et le ciblage des actions, en particulier des actions marketing / publicitaires.
- Le pilotage (l’analyse) de la performance des actions, grâce à des indicateurs business et clients.
Une entreprise qui cherche à déployer un projet data poursuit l’un, plusieurs ou tous ces objectifs à la fois.
La première étape d’un projet d’ingénierie de données consiste à prendre le temps de cadrer les objectifs du projet et les besoins auxquels il répond. L’infrastructure va vous permettre de mieux exploiter vos données, en particulier vos données clients. Mais pour quoi faire ? Dans quels buts ?
Nous proposons généralement aux clients que nous accompagnons d’organiser un atelier « Objectifs » en ouverture de projet pour sélectionner, prioriser et qualifier ensemble les besoins métiers auxquels le projet doit répondre.
Cet atelier réunit des représentants de tous les utilisateurs finaux des données, mais aussi bien entendu les intervenants techniques, la DSI. C’est d’ailleurs un point sur lequel il faut insister : la réussite du projet data repose pour beaucoup sur la qualité de la collaboration et de la communication entre les équipes métiers et l’équipe technique :
- L’équipe technique doit être à l’écoute des besoins métiers des utilisateurs finaux de l’infrastructure data. Mieux : elle doit comprendre ces besoins, les intégrer, les faire sien. Tous les développements techniques devront être faits en gardant à l’esprit la finalité métier.
- Les équipes métiers, les utilisateurs finaux du dispositif, doivent quant à eux être capable de formuler leurs besoins de manière précise et comprendre les contraintes (techniques, budgétaires) qui pèsent sur le projet.
Pourquoi rencontre-t-on aujourd’hui encore des organisations qui ne disposent pas de hub de données centralisé et organisé ? Bien souvent à cause d’un manque de compréhension entre l’équipe IT et les équipes métiers. La première manque souvent de compréhension des activités business, les deuxième d’expertise technique. Résultat : les données sont sous-exploitées.
Nous vous recommandons de désigner comme chef de projet une personne réunissant les deux compétences : métier et IT. C’est le meilleur moyen de faciliter la communication entre les deux types d’intervenants pendant la durée du projet. Dans nos accompagnements, nous faisons le pont entre la technique et le métier.
Plus de 100 entreprises accompagnées sur leurs projets CRM et Data
Cartelis accompagne les entreprises (B2C & B2B, de la startup au grand groupe) dans le cadrage et le déploiement de Projets CRM Marketing et Data.

2 – Mettre en place une méthodologie projet adaptée et rigoureuse
Pour réussir un projet data, vous devez définir le pourquoi (les objectifs) de manière précise et aligner toutes les parties prenantes sur ce pourquoi. Mais ce n’est pas tout. Vous devez également fixer un cadre méthodologique, définir un comment.
Voici nos convictions méthodologiques concernant les projets l’ingénierie data (mais cela s’applique aussi bien à d’autres familles de projets) :
- Prioriser les objectifs, les besoins métiers, en commençant par traiter les questions business clés, les objectifs structurants.
- Mettre en place un mode de suivi de projet adapté à l’organisation : réunions régulières, méthodologies adaptée (agiles, semi-agiles, classiques), outils de gestion de projet…
- Construire de manière itérative, en « lotifiant » la conception de l’infrastructure data. Nous privilégions systématiquement les démarches progressives avec et pour nos clients.
- Déployer des tests au fur et à mesure pour s’assurer que tous les process et traitements de données opérés par la nouvelle architecture IT sont fiables et sécurisés – et d’ajuster le plan d’actions si besoin.
- Monitorer les incréments de performance rendu possible grâce à la nouvelle infrastructure data. Quel impact de la nouvelle organisation sur la performance client et la connaissance client ? Cela suppose de mettre en place un dispositif de pilotage.
3 – Organiser l’adoption de l’infrastructure data par les utilisateurs
La nouvelle infrastructure data / architecture IT ne vaut que si elle est adoptée par les utilisateurs cibles. Cela implique de proposer aux équipes un accompagnement à la prise en main des nouveaux outils et de la nouvelle infrastructure. Cela passe par des sessions de formation, du coaching, mais aussi – point important – par l’implication des utilisateurs finaux dans le projet, notamment en phase de cadrage. Les équipes métiers doivent être actives dans la définition des objectifs et des besoins métiers.
Dans nos accompagnements, nous attirons toujours l’attention de nos clients sur l’importance de ce facteur humain. C’est la clé ultime de réussite du projet. Et c’est la raison pour laquelle les enjeux de transition, de conduite du changement doivent être anticipés dès l’amorce du projet data.
Discutons de votre projet
Besoin d'accompagnement à la conception et au déploiement de votre projet data ?
Prenons contactLes principales étapes de déploiement d’un Projet Data
Nous allons vous présenter de manière synthétique les principales étapes d’un projet l’ingénierie de données. Nous n’entrerons pas dans tous les détails, sachant que les détails du projet dépendent toujours de ses spécificités. En ce sens, chaque projet est unique.
#1 Le cadrage du projet
Comme nous l’avons rappelé plus haut, tout commence par un cadrage du projet. Vous devez formuler et prioriser les objectifs et les besoins métiers. En général, nous l’avons vu, le déclencheur du projet est le constat des incohérences de l’architecture IT en place : les données sont silotées, non-unifiées, difficilement transformables, parfois peu fiables et in fine difficilement utilisables…
Vous envisagez de construire une nouvelle infrastructure data ou d’améliorer l’architecture actuelle pour déployer vos cas d’usage liés à la connaissance client, à l’activation marketing et/ou au pilotage de la performance. Ce sont les trois finalités principales d’un projet data.
Vous cherchez à améliorer la consolidation, le traitement et l’exploitation de vos données ? Mais, pourquoi faire ? Prenez le temps d’identifier et prioriser vos besoins. C’est la première étape.
En fonction de l’ampleur de vos besoins et du niveau de maturité actuel de votre infrastructure data, deux options s’ouvriront à vous :
- Une refonte substantielle de votre architecture IT, impliquant la mise en place d’une base de données centralisée (de type Data Warehouse, par exemple), le remplacement de certains ou de la plupart des outils, l’évolution de votre modèle de données, etc.
- Une évolution à la marge et pragmatique de l’infrastructure existante pour mettre en place quelques cas d’usage précis.
Le choix entre les options dépend 1/ d’où vous partez, 2/ de vos objectifs et 3/ de vos ressources et contraintes diverses (budget, délais…).
#2 Le diagnostic de l’infrastructure data existante
La deuxième étape classique est un état des lieux de l’existant. Il s’agit de répondre aux questions suivantes :
- Quelles sont les données disponibles ?
- Quelles sont les données / indicateurs manquant(e)s ?
- Où sont stockées les données ?
- Quels sont les systèmes à disposition : outils et bases de données ?
- Quels sont les process et les traitements de données à date ?
- Comment les données circulent-elles dans le système d’information ? Quels sont les flux de données entre les différents systèmes ? Quels mécanismes (API, connecteurs, exports manuels) ? Quels dessins d’enregistrement ?
- Quels sont les cas d’usage actuel des données ?
- Quelle est la qualité des données ? Quelles sont les règles de mise à jour, de nettoyage ?
- Quelles sont les sources de données, les destinations ?
Bref, il faut mener un audit de la situation actuelle. Avec les clients que nous accompagnons, nous procédons à des entretiens individuels, à des réunions, à des consultations documentaires pour construire une vision claire de l’existant – préalable indispensable à la phase de conception de l’infrastructure cible.
Une fois que nous connaissons les objectifs du projet et la situation actuelle, nous pouvons sereinement passer à l’étape suivante : la définition de l’infrastructure data cible – celle qui permettra de répondre aux besoins métiers des équipes.
#3 La conception de l’architecture cible
Cette étape consiste à imaginer les contours de la future architecture data et technologique. On définit : les familles d’outils à utiliser, la place (le rôle) de chaque outil dans la future organisation, les interactions entre les différents outils.
Dans nos accompagnements, nous proposons en général 2, 3 ou 4 architectures IT possibles en fonction de plusieurs critères sur lesquels nous allons revenir dans un instant. Pour chaque architecture, nous proposons une cartographie et un passage en revue des avantages, des limites et des contraintes associées.
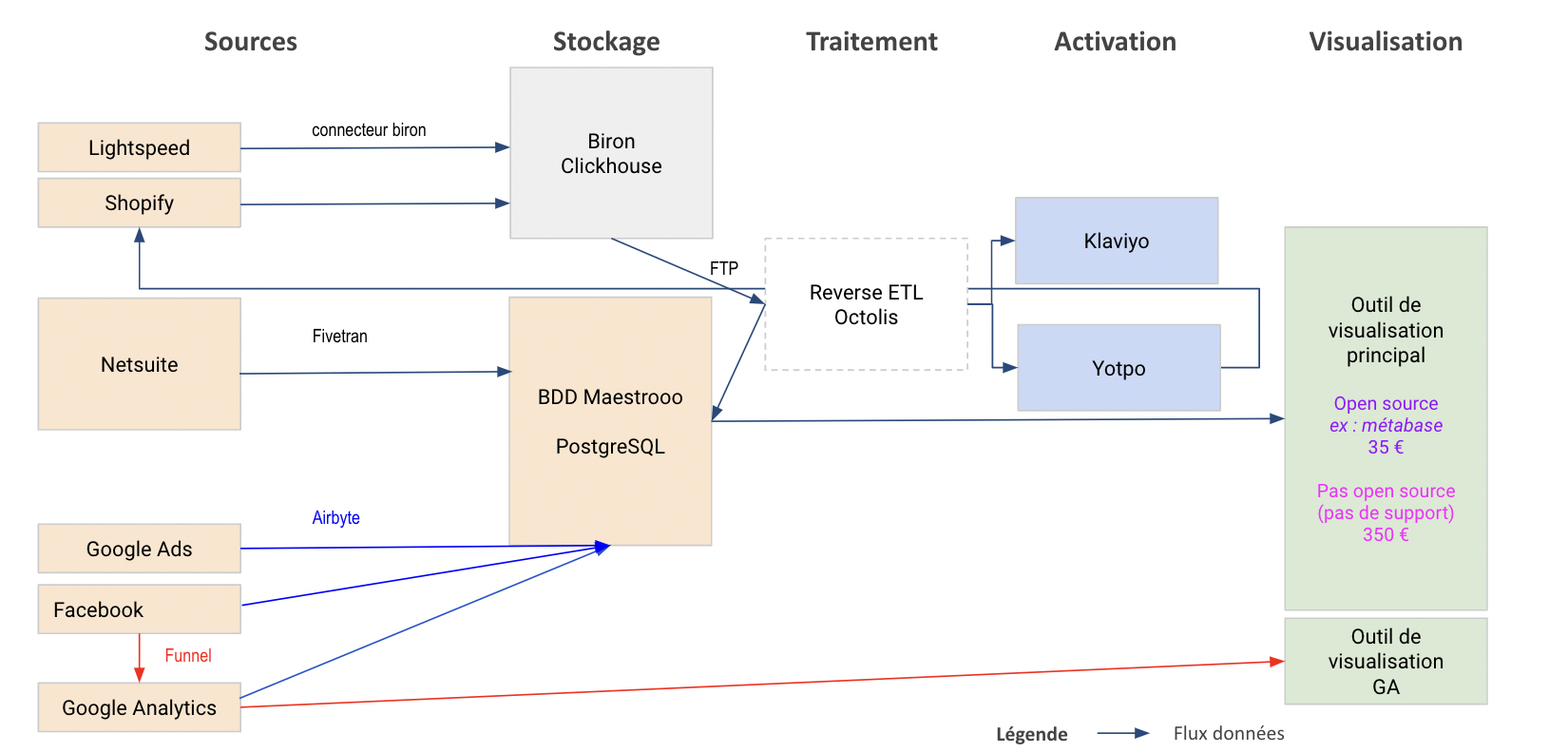
Les principaux critères qui influencent la conception et le choix d’une nouvelle infrastructure data sont :
- Les besoins métiers. Par exemple, si votre entreprise souhaite mettre en place un dispositif complexe de pilotage de la performance marketing, il est possible qu’il soit nécessaire de déployer un outil avancé de Business Intelligence et de créer une base de données centrale qui alimentera l’outil de BI. Les contours de l’architecture cible sont en partie dictés par les besoins métiers. Mais ce n’est pas le seul critère…
- L’architecture existante. Si vous disposez d’une base de données MySQL et que vous n’avez pas l’intention de la remplacer, cela aura un impact évident sur votre future architecture IT. A moins d’envisager une refonte complète de votre infrastructure, à moins de vouloir remplacer tous vos outils et toutes vos bases de données, l’architecture existante influence les contours de l’architecture cible.
- Les contraintes organisationnelles. Si vous ne disposez pas d’une équipe IT au sein de votre entreprise, vous devrez choisir des outils et des systèmes faciles à maintenir et à utiliser par les équipes métiers. Le niveau de compétences des équipes internes influence le choix des technologies.
- Les contraintes de sécurité. Le contrôle des données est un enjeu majeur pour les entreprises, en particulier celles qui gèrent des données sensibles (données financières, données médicales…). Ces contraintes sécuritaires influencent de plus en plus le choix des technologies cloud, les entreprises ayant de plus en plus tendance à privilégier des technologies stockées sur des serveurs européens.
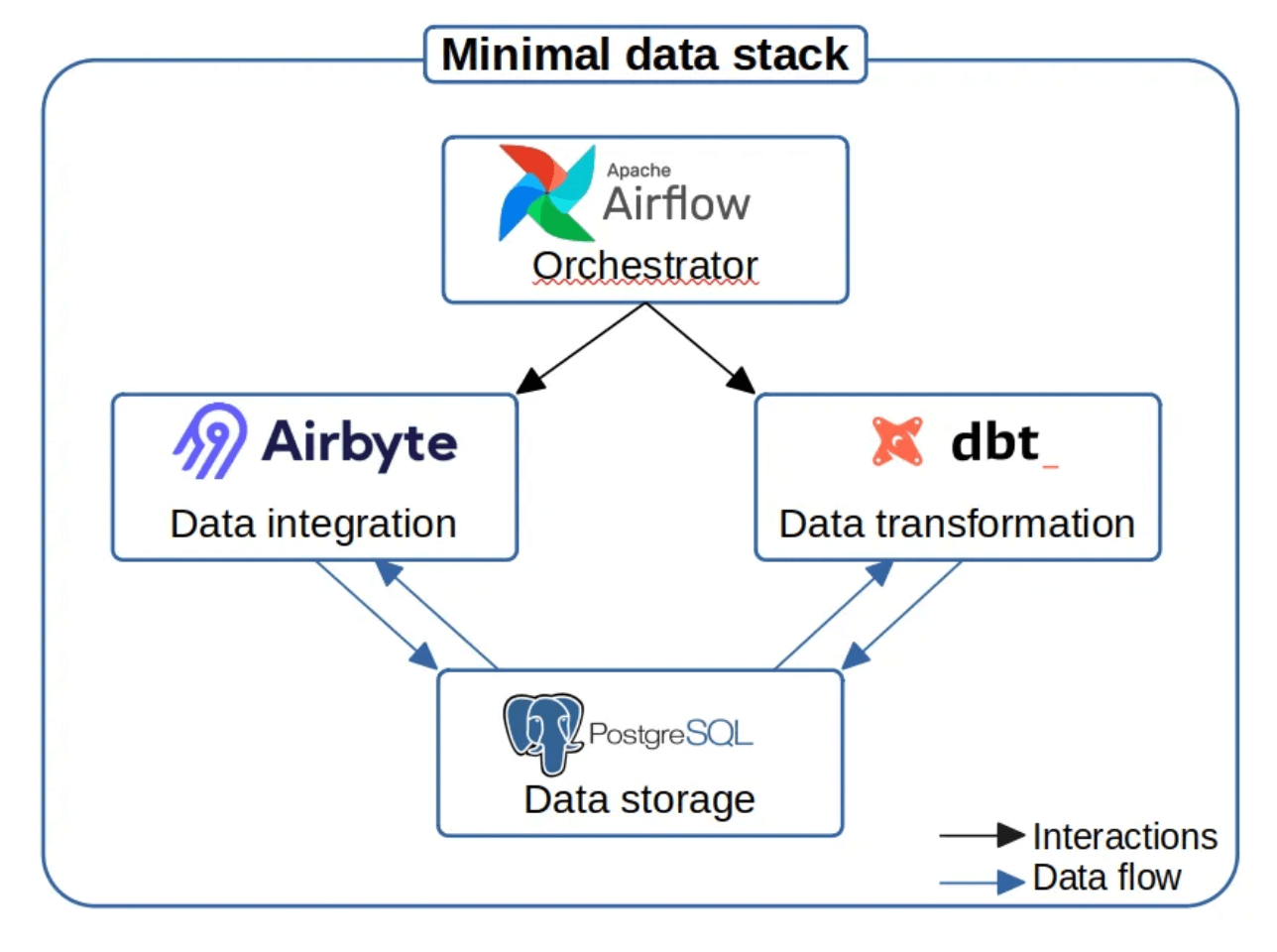
- Les contraintes financières. Les contraintes financières de l’entreprise ont aussi un impact sur les choix technologiques. Si vous disposez d’un budget très limité, nous pourrions vous recommander une architecture IT basée sur des systèmes open source. Nous abordons cette option dans un article que nous avons publié sur Medium et qui est intitulé « Setting up an open-source modern data stack« . Nous y présentons un modèle de stack data 100% open source, constituée de 4 outils piliers : PostgreSQL pour le stockage des données, Airbyte pour l’intégration des données, dbt pour la transformation des données et Apache Airflow pour l’orchestration des données.
Discutons de votre projet
Besoin d'accompagnement à la conception et au déploiement de votre projet data ?
Prenons contact#4 Le choix des outils
Une fois l’architecture IT choisie, nous pouvons passer au choix des outils. En fonction de l’infrastructure choisie, vous allez avoir besoin de sélectionner un outil de Business Intelligence, une base de données cloud, un Reverse ETL, un outil de transformation des données ou encore une suite CRM. Nous ne détaillerons pas le process de sélection des outils. Nous l’avons déjà fait abondamment dans d’autres articles vers lesquels nous vous renvoyons. Nous vous invitons notamment à découvrir nos articles dédiés à la rédaction du cahier des charges.
- Rédiger un cahier des charges CRM – Le guide complet
- Customer Data Platform – Réussir son cahier des charges
Le cahier des charges est le document cadre qui sert de base aux échanges avec les éditeurs éligibles. Le logiciel est choisi au terme d’un processus qui incluent des rencontres éditeurs, des démonstrations scénarisées et des évaluations. On parle de « RFP » (Request for Proposal) pour qualifier cette démarche structurée de sélection des outils.
Nous avons produit des comparatif de logiciels pour la plupart des familles d’outils mobilisées dans les infrastructures data :
- Business Intelligence – Les meilleurs outils de BI
- Comparatif complet des logiciels ETL
- Comparatif des meilleurs outils de Data Prep
- Data management – Définition & Guide
- Les outils de référence en Data Science
Surtout, nous vous invitons à télécharger notre Benchmark des outils de la « Stack Data Moderne ». C’est une ressource complète qui vous donnera une bonne vision des principales familles d’outils et des principaux outils pour chaque famille. La ressource est gratuite, profitez-en !
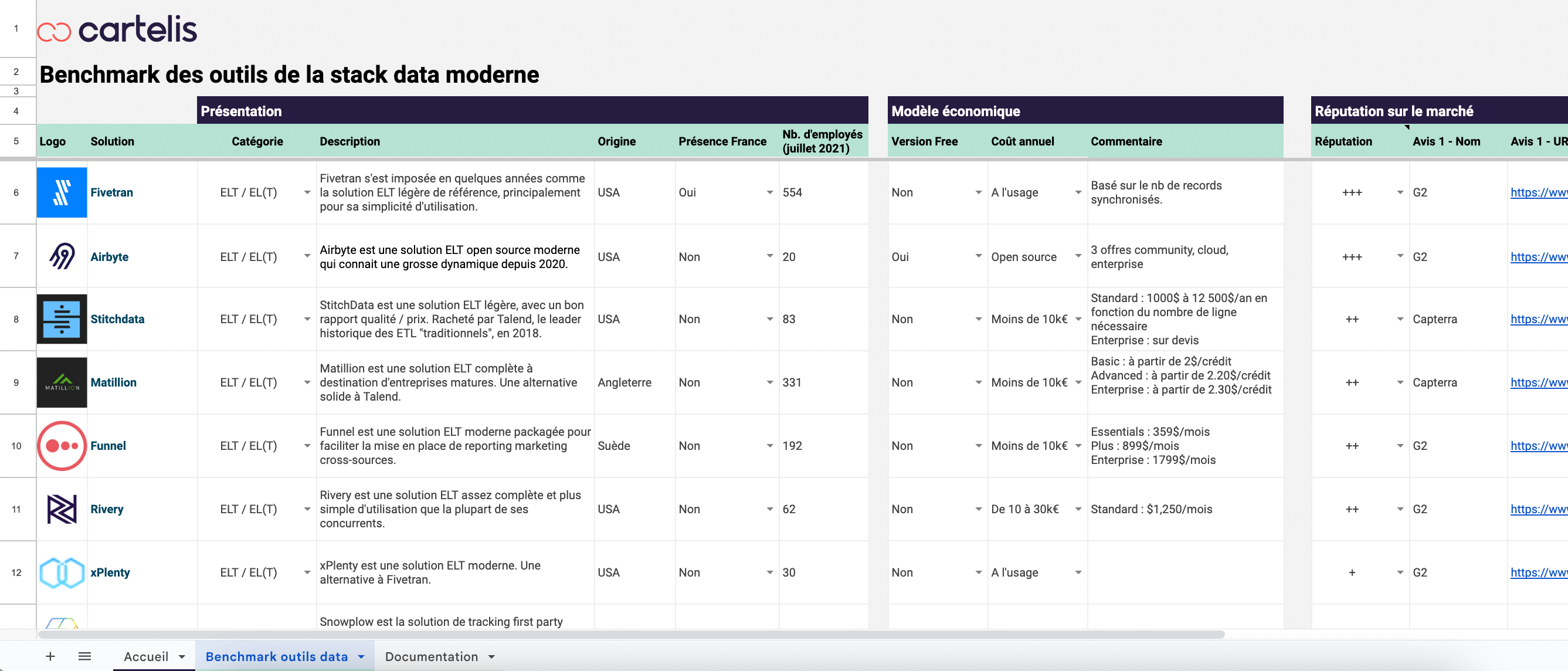
Benchmark des outils de la Stack Data Moderne
Téléchargez notre benchmark des meilleures technologies pour construire ou améliorer votre infrastructure data.
#5 Le déploiement de la nouvelle infrastructure data
La phase de déploiement comprend un certain nombre d’étapes techniques. Nous n’entrerons pas dans les détails, car ce n’est pas l’objet de ce guide mais nous allons néanmoins les principaux sujets à traiter au titre du déploiement d’une infrastructure data :
- La personnalisation du modèle de données. Les modèles de données désignent la manière dont les données sont enregistrées dans les systèmes, les outils et les bases. Si vous décidez de déployer un Data Warehouse, par exemple, vous allez devoir définir les différents champs qui constitueront vos tables de données.
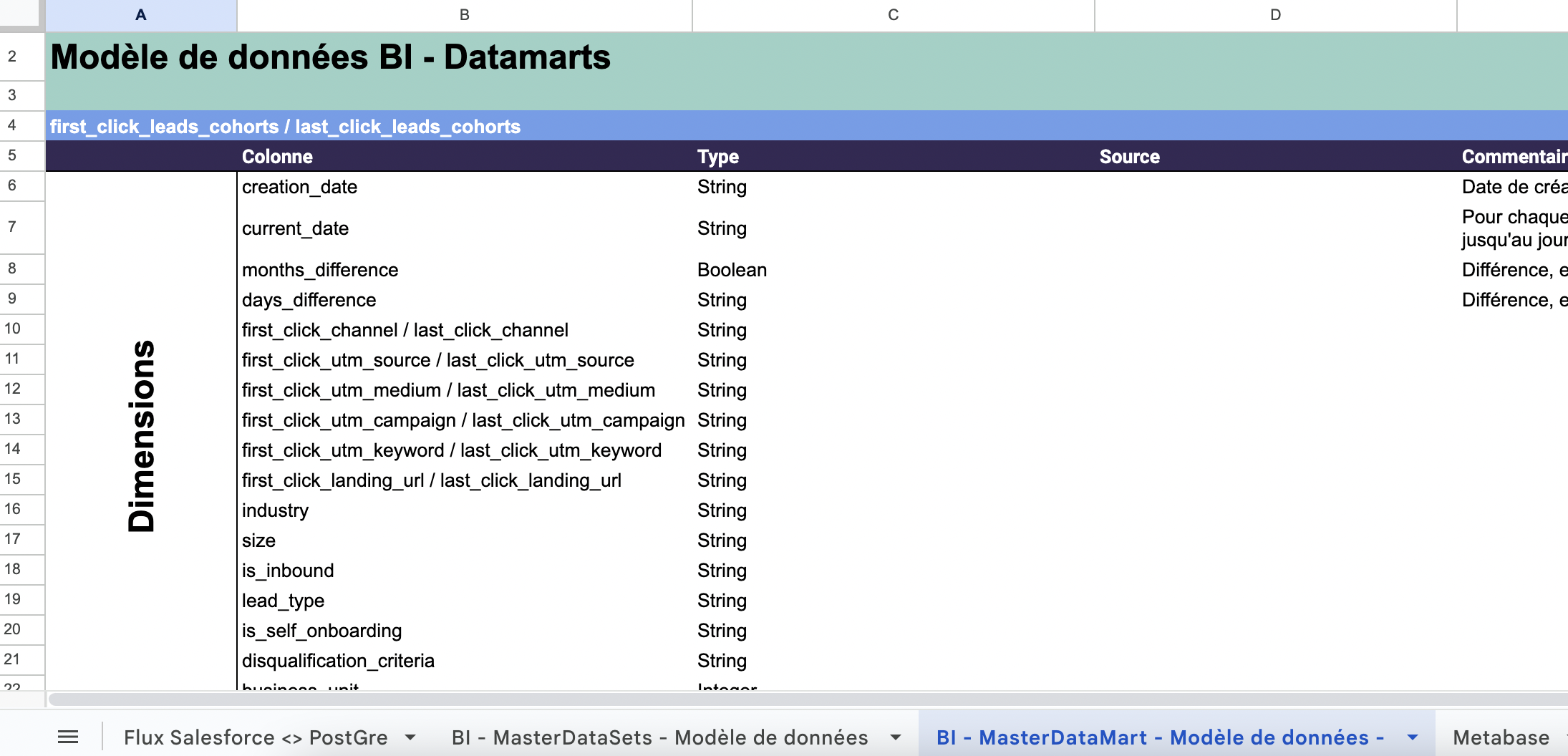
- La migration des données historiques. Si vous décidez de changer de base de données, vous allez devoir traiter la migration des données du système actuel vers le nouveau système. C’est un sujet complexe. Vous devez identifier les champs / objets que vous souhaitez conserver et concevoir les dessins d’enregistrement dans le nouveau système (mapping). Remarque : les projets de migration de données sont souvent l’occasion de faire un petit nettoyage de printemps.
- La mise en place des flux de données entre les différents systèmes. Pour prendre une métaphore, disons qu’il s’agit d’installer la tuyauterie qui va permettre aux données de circuler entre vos systèmes.
- La mise en place des process et traitements. Le but est de définir la manière dont les équipes vont utiliser la nouvelle infrastructure data. Cela intègre les règles de mises à jour des données.
- La phase de « recette ». Cette étape, cruciale, consiste à s’assurer que les données et les indicateurs qui apparaissent dans vos nouveaux tableaux de bord et outils sont conformes à vos « sources de vérité » historiques. C’est un moyen sûr de vérifier que les process, traitements, flux et réglages sont OK. Ci-dessous, un exemple de cahier de recette produit dans le cadre de l’une de nos missions d’accompagnement.
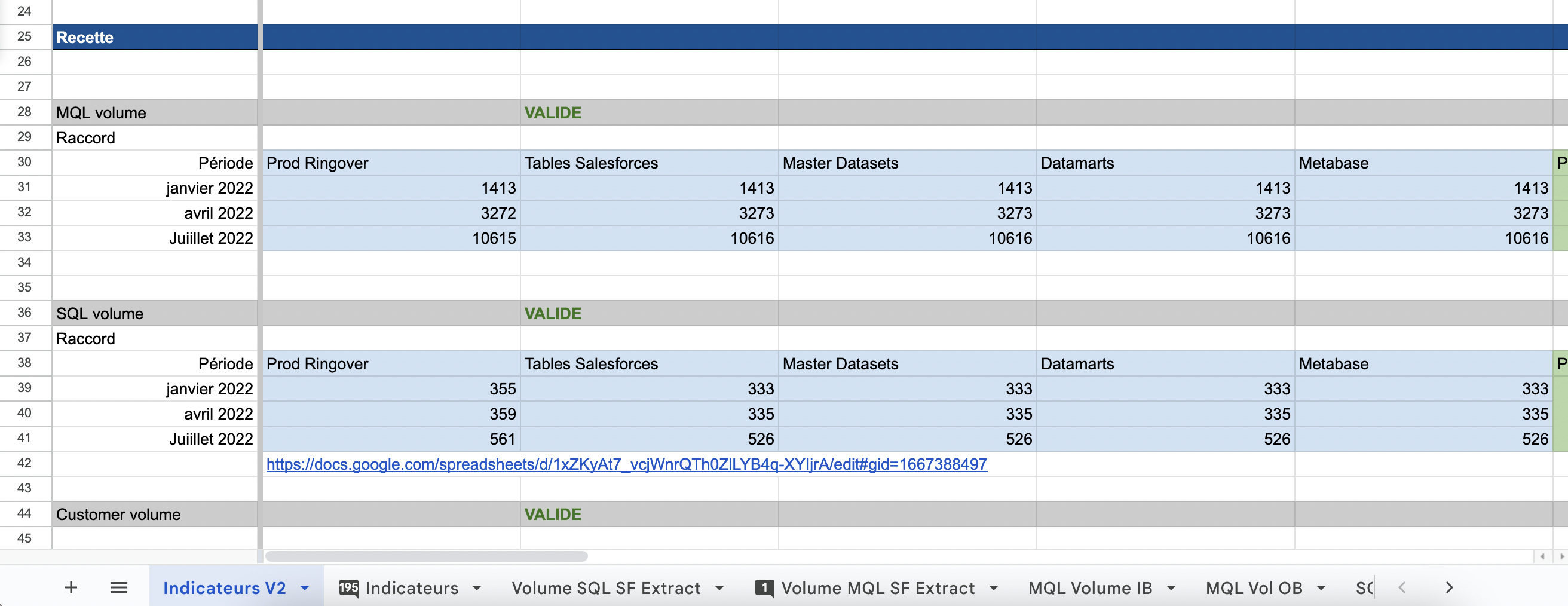
Si cela vous intéresse, nous avons conçu un template de cahier de recette de dashboard. Il permet d’organiser et de suivre les tests de vos tableaux de bord. Cette ressource est également 100% gratuite, donc n’hésitez pas à la télécharger !
L’étape de déploiement est l’étape la plus technique. Elle comprend un nombre important de chantiers. Si vous souhaitez avoir plus de détail, nous vous invitons à découvrir les suggestions de lecture proposées dans le menu situé à gauche de cet article.
N’oubliez pas que le déploiement technique n’est pas le fin mot de l’histoire. Il faut ensuite organiser l’appropriation du nouveau dispositif par les utilisateurs finaux de la nouvelle infrastructure data. C’est l’une des trois clés de réussite que nous avons identifié dans la première section de l’article.
Vous avez un projet data ? Entrons en contact !
Vous souhaitez moderniser votre infrastructure data pour déployer de nouveaux cas d’usage de vos données clients, améliorer votre performance marketing, enrichir votre connaissance client?
Nous aidons les entreprises à mieux exploiter leurs données. Plus de 100 entreprises nous ont fait confiance. Nous sommes peut-être en mesure de vous accompagner dans votre projet data. N’hésitez pas à nous contacter pour un premier échange rapide.