En matière de gestion des données, toutes les entreprises sont confrontées au même défi : comment gérer, exploiter et valoriser efficacement des volumes croissants de données hétérogènes, tout en maintenant agilité et flexibilité ?
Les architectures data traditionnelles, centralisées et monolithiques, montrent leurs limites face à la complexité et la rapidité d’évolution des besoins métier.
C’est dans ce contexte qu’a émergé le concept de Data Mesh, proposé par Zhamak Dehghani, CEO de NextData. On peut le traduire par « maillage de données » ou « réseau de données ».
Cette approche – pour faire vite – consiste à passer d’une logique centralisée à une logique distribuée, où les données sont traitées comme un produit et gérées de manière autonome par les différentes fonctions métiers. On vous explique tout.
Qu’est-ce que le Data Mesh ?
Définition du Data Mesh
Le Data Mesh est une option d’architecture qui vise à décentraliser la gestion des données au sein de l’entreprise.
Contrairement aux architectures traditionnelles où les données sont gérées de manière centralisée par une équipe IT, le Data Mesh propose de distribuer la responsabilité des données aux différents domaines métier qui les produisent et les utilisent.
Concrètement, chaque domaine (par exemple, la finance, les ressources humaines, la production) devient responsable de ses propres données, depuis leur collecte jusqu’à leur mise à disposition pour les autres domaines.
Les données sont ainsi traitées comme un produit, avec une qualité, une documentation et un contrôle d’accès clairement définis.
Les 4 piliers du Data Mesh
Les quatre piliers du Data Mesh sont les suivants :
- Un pilotage par domaine : les données sont organisées autour des domaines métier plutôt que des fonctions techniques. Chaque domaine a la responsabilité de ses données.
- Les données en tant que produit (Data as a product) : les données sont traitées comme un produit, avec une valeur clairement identifiée pour les consommateurs. Elles sont documentées, testées et livrées avec un niveau de qualité garanti.
- Libre-service (Self-service) : les domaines sont autonomes dans la gestion de leurs données. Ils fournissent des interfaces en libre-service permettant aux autres domaines de découvrir et d’accéder facilement aux données dont ils ont besoin.
- Gouvernance fédérée : la gouvernance des données est assurée de manière fédérée. Concrètement, des standards communs sont définis au niveau global, mais chaque domaine est responsable de leur application locale.
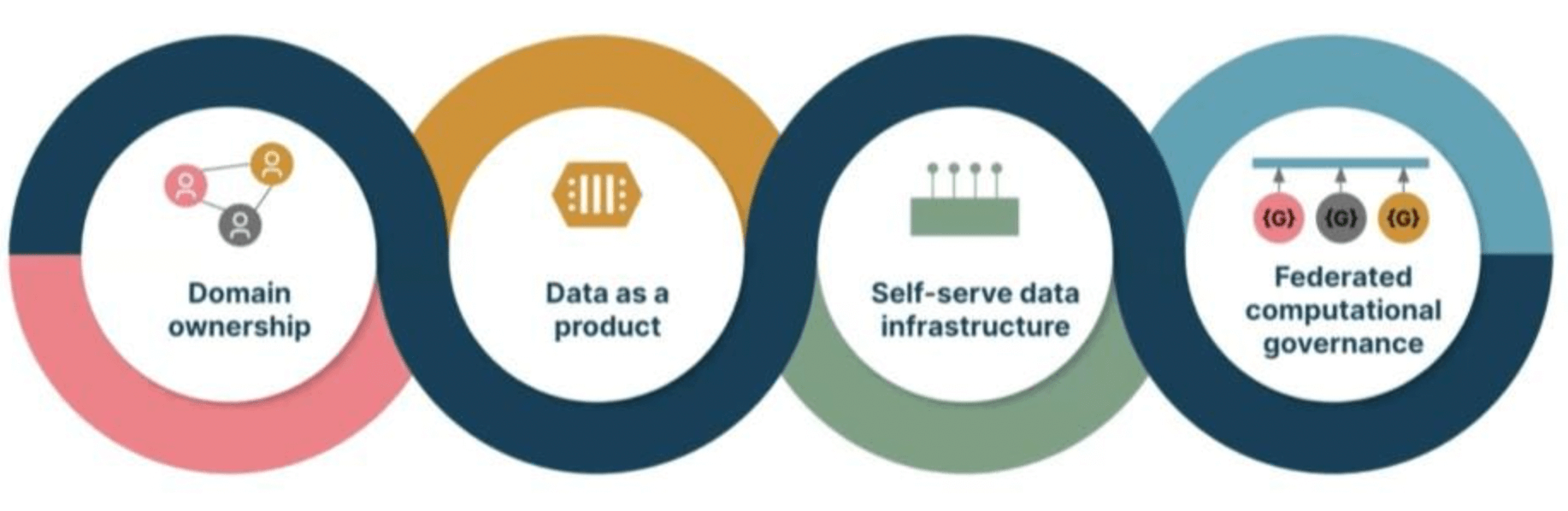
Si on voulait résumer le Data Mesh, on pourrait dire qu’il consiste dans son essence à redistribuer la responsabilité des données au plus près de ceux qui les produisent et les utilisent, tout en maintenant une cohérence globale grâce à une gouvernance fédérée.
On comprend pourquoi c’est une approche qui favorise l’agilité, la qualité et la valorisation des données à l’échelle de l’entreprise.
Si vous vous intéressez aux sujets data, ces articles pourraient aussi vous intéresser :
Le Data Mesh, une réponse aux limites des architectures data traditionnelles
Les architectures data traditionnelles, comme les data warehouses ou les data lakes, ont longtemps été la norme pour gérer les données d’entreprise – mais avec l’explosion du volume et de la variété des données, ces approches centralisées montrent leurs limites.
Première limite : elles ont tendance à créer des silos de données. Chaque service gère ses propres données, sans réelle communication ou partage avec les autres, ce qui conduit souvent à des incohérences, des doublons et une difficulté à avoir une vue d’ensemble des données de l’entreprise.
De plus, ces architectures sont souvent complexes et rigides. Ajouter de nouvelles sources de données ou modifier les schémas existants peut demander des efforts considérables et ralentir la capacité de l’entreprise à s’adapter à de nouveaux besoins ou opportunités.
Autre point faible, la gouvernance des données est souvent centralisée au niveau de l’équipe IT. Cela crée un goulot d’étranglement et une dépendance des métiers vis-à-vis de l’IT pour accéder aux données dont ils ont besoin. Les délais s’allongent et c’est l’agilité qui en pâtit.
Enfin, last but not least, ces architectures peuvent atteindre leurs limites en termes de scalabilité. Concrètement, quand les volumes de données deviennent très importants, il devient difficile et coûteux de tout gérer de manière centralisée.
Même si elles ont répondu aux besoins pendant de nombreuses années, les architectures data traditionnelles peinent à suivre le rythme de l’évolution des données et des besoins métier. C’est pour répondre à toutes ces limites qu’a émergé le concept de Data Mesh.
Les avantages du Data Mesh
Voyons plus en détail les principaux avantages de l’approche Data Mesh.
Le premier avantage, comme nous l’avons déjà vu, c’est que le Data Mesh favorise l’autonomie et la responsabilisation des domaines métier. C’est un point clé. L’architecture Data Mesh donne à la fois aux métiers plus de liberté, d’autonomie mais aussi de responsabilité dans la gestion et la manipulation des données.
L’approche « Data as a Product » a aussi pour conséquence d’améliorer la confiance dans les données. Les consommateurs de données, qu’ils soient internes ou externes, peuvent utiliser les données en toute sérénité.
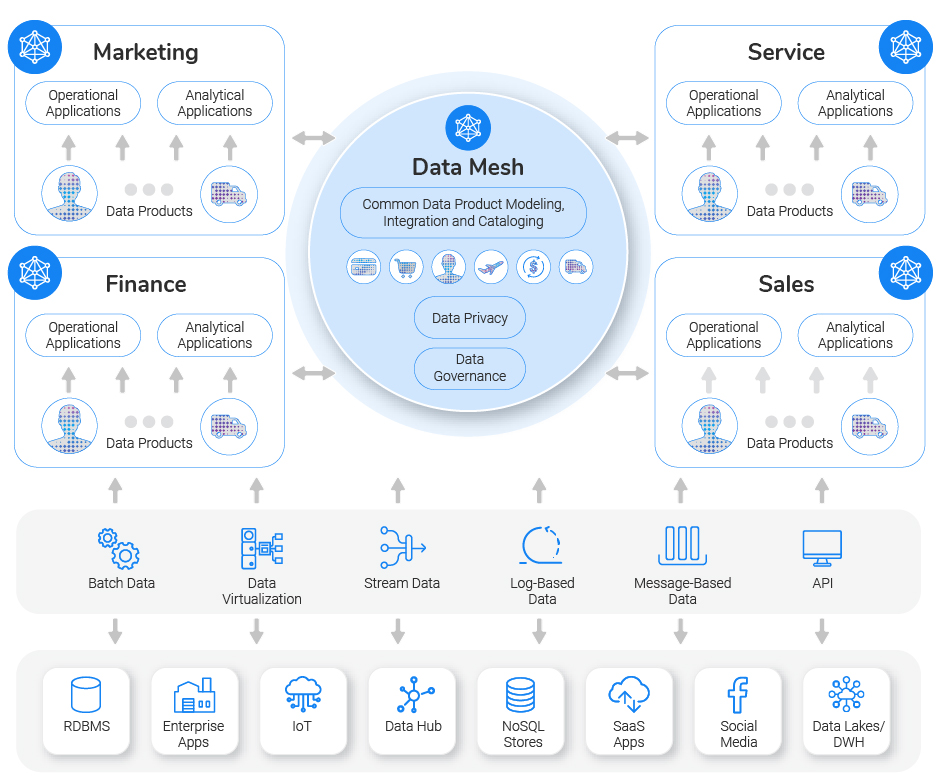
Le Data Mesh offre également une meilleure scalabilité que les architectures classiques, centralisées. Avec une architecture distribuée, il est beaucoup plus facile d’ajouter de nouveaux domaines ou de gérer des volumes croissants de données. Et chaque domaine peut évoluer indépendamment, sans impacter les autres.
Le Data Mesh accélère aussi le time-to-value, c’est-à-dire le temps nécessaire pour extraire de la valeur des données. Les interfaces self-service et la documentation des traitements permettent aux utilisateurs d’accéder plus rapidement aux données dont ils ont besoin, sans passer par de longues demandes à l’IT…(le calvaire de toutes les utilisateurs métiers !).
Les défis de la mise en place d’un Data Mesh
Le Data Mesh a de nombreux atouts à faire valoir.
Ceci dit, il faut être conscient que la mise en place d’un Data Mesh n’est pas un long fleuve tranquille. Elle implique un véritable changement de paradigme et soulève un certain nombre de défis.
Le premier défi – sans doute le plus important – est culturel.
Passer d’une gestion centralisée des données à une approche distribuée nécessite un changement de mentalité. Il faut que les équipes apprennent à travailler de manière autonome et à collaborer différemment. Tout cela demande du temps, de la communication et un sponsorship fort de la direction.
Il faut ensuite réussir à définir de manière cohérente et pertinente les domaines et les responsabilités. Et le fait est que découper l’entreprise en domaines cohérents, avec des frontières claires, n’est pas toujours évident. Cela demande une très bonne compréhension du métier et de ses processus. Il faut aussi définir les rôles et les responsabilités de chacun : qui produit quelles données, qui y a accès, qui en assure la qualité…
La mise en place de la gouvernance fédérée est un autre point de vigilance. Il faut en effet trouver le juste équilibre entre autonomie des domaines et cohérence globale. C’est parfois un travail d’équilibriste. Pour gérer ce challenge, il est important de définir au niveau de l’entreprise des standards et des bonnes pratiques…sans entraver pour autant l’agilité de chaque domaine.
Ajoutons que le Data Mesh demande de nouvelles compétences et de nouveaux rôles. C’est un autre point à anticiper. Une architecture Data Mesh ne peut bien fonctionner que si des profils hybrides, à la croisée du métier et de la technique, sont mobilisés. Le rôle de Data Product Owner, en particulier, est clé pour gérer les données comme un produit. Il faut aussi des compétences en architecture, en qualité des données, en gouvernance…
Les étapes clés pour adopter le Data Mesh
#1 Identifiez les domaines et les cas d’usage
La première étape consiste à bien analyser votre organisation et la découper en domaines métier cohérents.
Un « domaine », dans le sens précis qui lui est donné dans l’approche Data Mesh, c’est un ensemble de données et de fonctionnalités liées à un aspect spécifique de votre activité. Par exemple : la gestion des clients, la logistique, la facturation…
Une fois les domaines identifiés, il faut pour chaque domaine comprendre les principaux cas d’usage des données :
- Quelles données sont produites, par qui, pour quoi faire ?
- Quels sont les besoins en termes d’analyse, de reporting, de prise de décision ?
Cette compréhension fine des usages vous permettra de prioriser les domaines et les cas d’usage à adresser en premier.
Un conseil : commencez par des projets pilotes sur des domaines à fort potentiel et à forte valeur ajoutée, avant de généraliser à toute l’organisation. Cette approche progressive est celle que nous recommandons toujours à nos clients.
#2 Définissez les interfaces et les contrats de données
Une fois les domaines et les cas d’usage identifiés, il faut définir comment ces domaines vont interagir et partager leurs données.
C’est tout l’enjeu des interfaces et des contrats de données.
Pour chaque domaine, il faut définir les interfaces par lesquelles il va exposer ses données : il peut s’agir d’APIs, d’événements, de flux de données…L’objectif est de rendre les données facilement accessibles et utilisables par les autres domaines.
Mais exposer les données ne suffit pas, il faut aussi s’accorder sur leur qualité et leur gouvernance.
C’est le rôle des contrats de données, qui définissent les engagements du domaine producteur envers les domaines consommateurs. Ces contrats couvrent des aspects comme la fraîcheur des données, leur exhaustivité, leur conformité réglementaire…
Les contrats de données incluent aussi les modalités d’accès : comment s’authentifier, quelles sont les données accessibles à qui, y a-t-il une tarification ?
Les deux – interfaces et contrats – doivent être documentés et facilement découvrables par tous les acteurs.
#3 Mettez en place l’infrastructure et les outils
Le Data Mesh repose sur une architecture distribuée, où chaque domaine est autonome dans la gestion de ses données.
Pour mettre en place cette architecture, il faut choisir les bonnes technologies et les bons outils : les bases de données pour stocker les données, mais aussi les outils de traitement pour les transformer, les outils de qualité pour les valider, les outils de sécurité pour les protéger…
Le choix de ces technologies dépend des besoins et des compétences de chaque domaine.
L’objectif est de donner à chaque domaine les moyens de gérer ses données de manière autonome et efficace, tout en assurant une cohérence globale.
Pour faciliter cette cohérence, nous recommandons de mettre en place des outils transverses, comme par exemple un catalogue de données pour référencer et découvrir les données disponibles, ou bien des pipelines de données pour automatiser les flux inter-domaines.
#4 Assurez la gouvernance et la qualité des données
L’autonomie des domaines ne signifie pas l’anarchie.
Pour assurer une cohérence globale et une utilisation fiable des données, il faut mettre en place une gouvernance adaptée. Cette gouvernance doit être dite « fédérée« , c’est-à-dire qu’elle définit des standards et des principes communs au niveau de l’entreprise, mais laisse chaque domaine responsable de leur application (pensez à l’organisation politique des Etats-Unis).
Concrètement, cela peut se traduire par des modèles de données communs, des règles de sécurité et de confidentialité partagées, des processus de contrôle qualité harmonisés…
Chaque domaine doit mettre en place ces éléments pour ses propres données et s’assurer de leur respect. Il faut aussi définir et suivre des indicateurs de qualité des données pour identifier les points d’amélioration.
Enfin, des rôles doivent être établis, à commencer par celui de Data Product Owner, qui sera responsable de la qualité et de la mise à disposition des données de son domaine.
#5 Accompagnez le changement et formez les équipes
Le Data Mesh n’est pas qu’un changement technologique, c’est aussi et surtout un changement culturel et organisationnel.
Pour que cette nouvelle approche soit un succès, il faut embarquer toutes les équipes dans la démarche. C’est un point clé et cela passe d’abord par une communication claire sur la vision et les bénéfices attendus du Data Mesh. Il faut expliquer pourquoi on fait ce choix, ce que ça va changer concrètement, ce qu’on attend de chacun, etc.
Il faut aussi donner aux équipes les moyens de jouer leur nouveau rôle. Cela passe par de la formation sur les nouvelles compétences requises : comment concevoir et opérer un produit de données, comment assurer la qualité et la sécurité des données, comment collaborer avec les autres domaines…
En définitive, c’est un vrai plan de conduite du changement qu’il faut mettre en place, avec un accompagnement dans la durée.
#6 Mesurez et optimisez en continu
L’adoption du Data Mesh n’est pas un projet avec une fin, c’est une démarche d’amélioration continue.
Une fois les premiers domaines lancés, il faut mettre en place des indicateurs pour mesurer l’efficacité et les bénéfices de cette nouvelle approche. Cela peut inclure des métriques sur la qualité des données, le temps d’accès aux données, la satisfaction des utilisateurs, les coûts d’infrastructure…
C’est en analysant régulièrement ces indicateurs que vous pourrez identifier les axes d’amélioration et faire évoluer votre Data Mesh en continu. C’est une démarche itérative, où chaque domaine apprend des autres, partage ses bonnes pratiques et ajuste son fonctionnement. Il faut voir le Data Mesh comme un organisme vivant, qui s’adapte en permanence aux besoins de l’entreprise et de ses clients.
La clé est de commencer petit, sur des projets pilotes, et d’apprendre en marchant. Avec une vision claire, un sponsorship fort, et un accompagnement de tous, le Data Mesh peut devenir une réalité et un puissant accélérateur de votre stratégie data.
Cartelis vous accompagne dans votre projet Data Mesh
Vous avez entendu parler du Data Mesh et vous vous demandez si cette approche pourrait répondre aux défis data de votre entreprise ? C’est une question légitime, mais la réponse n’est pas univoque.
Le Data Mesh n’est pas une solution miracle qui conviendrait à tous les contextes. Selon votre maturité data, votre organisation, votre culture d’entreprise, cette approche peut être pertinente… ou pas !
C’est là que Cartelis peut vous aider. Avec notre expertise data et notre expérience des architectures data dans de multiples secteurs, nous pouvons vous accompagner dans votre réflexion.
Notre mission ? Analyser avec vous la faisabilité et la pertinence d’une approche Data Mesh dans votre contexte spécifique.
Notre méthode est basée sur l’écoute et le sur-mesure. Nous prenons le temps de comprendre vos enjeux business, vos contraintes techniques, vos ambitions data. À partir de là, nous pouvons vous aider à définir la meilleure stratégie data, qu’elle soit basée sur un Data Mesh ou sur une autre architecture.
Si le Data Mesh s’avère être la bonne option pour vous, nous pouvons vous accompagner de bout en bout dans sa mise en place : de la conception de l’architecture à la conduite du changement, en passant par le pilotage du déploiement. Notre objectif est de faire de votre Data Mesh un véritable levier de performance, aligné sur vos objectifs métier.
Mais notre plus grande fierté, c’est quand nous arrivons à rendre vos équipes totalement autonomes dans la gestion et l’exploitation de votre Data Mesh. C’est pour nous le signe d’une mission réussie !
Alors, curieux d’explorer le potentiel du Data Mesh pour votre entreprise ? Discutons-en !