Les parcours clients sont devenus si fragmentés qu’un même individu peut apparaître sous des dizaines d’identités différentes dans les systèmes d’une entreprise. Entre les comptes en ligne, les appareils connectés et les interactions hors ligne, relier ces identités est un casse-tête. Résultat : une vision client morcelée qui complique la personnalisation des expériences et fausse les analyses.
Chez Cartelis, nous accompagnons régulièrement des entreprises confrontées à cette problématique. La résolution d’identité – ou ID Resolution – est une étape clé dans tout projet data visant à structurer la connaissance client. Son objectif ? Réconcilier les identités dispersées, dédupliquer et unifier les données pour obtenir des profils clients uniques et persistants.
Discutons de votre projet
Besoin d'accompagnement à la conception et au déploiement de votre projet data ?
Prenons contactSommaire
Qu’est-ce que la résolution d’identité (ID Resolution) ?
Définition et objectifs
La résolution d’identité, ou « Identity Resolution » en anglais, désigne le processus qui consiste à réconcilier les différentes identités d’un même individu disséminées dans plusieurs sources de données et systèmes.
L’objectif est de regrouper ces identifiants épars (email, numéro de client, identifiant d’appareil, cookie…) pour reconstituer une identité unique et obtenir une vue consolidée de chaque profil.
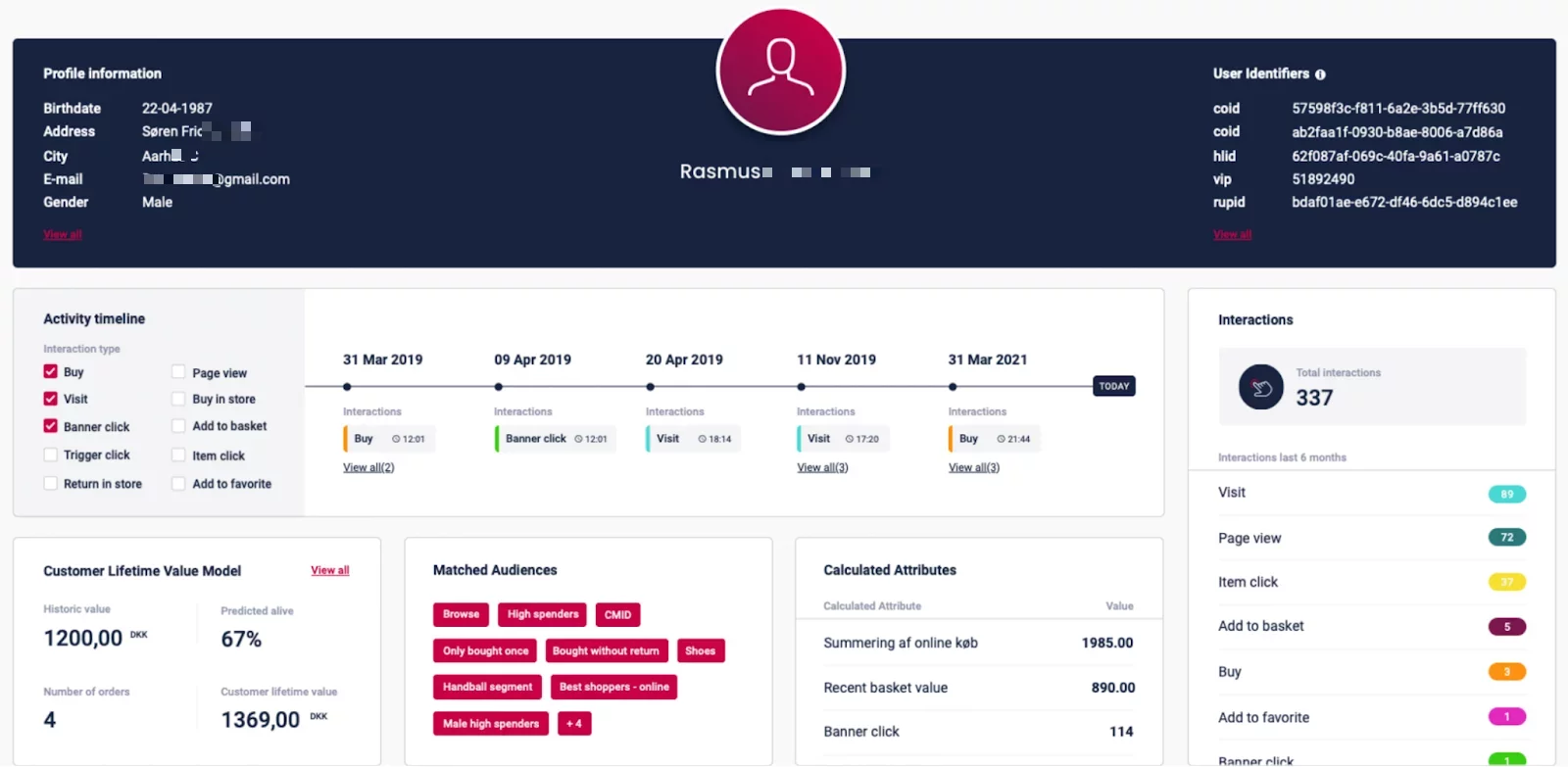
À travers ce rapprochement, la résolution d’identité permet d’unifier la connaissance client en reliant toutes les informations capturées sur un individu lors de ses interactions avec une marque ou une entreprise (données personnelles, comportementales, transactionnelles…). Les fiches clients 360, comme celle ci-dessous (construite dans la CDP Raptor), matérialisent le résultat du processus de résolution d’identité.
Enjeux sous-jacents de l’ID resolution : personnalisation, vision 360°, conformité RGPD
Au-delà de l’unification des données, la résolution d’identité répond à plusieurs enjeux marketing & business :
- La personnalisation : pouvoir identifier un client de façon unique, quel que soit le point de contact, permet d’offrir des messages et des expériences ultra-personnalisés et contextualisés. En clair, qui dit résolution d’identité dit meilleure connaissance client, qui dit meilleure connaissance client dit meilleure personnalisation CRM/marketing.
- La vision client 360° : en reliant les différentes facettes de l’identité et du parcours d’un client, la résolution d’identité permet d’obtenir une vue exhaustive de son profil, de ses préférences et de son historique. La résolution d’identité permet, entre autres, de construire des fiches clients exhaustives.
- La conformité RGPD : pouvoir faire le lien entre les données des clients est un prérequis pour respecter leurs droits (accès, rectification, portabilité, oubli…). Sans une résolution d’identité efficace, il est difficile de retrouver l’ensemble des informations associées à un même individu, ce qui a évidemment une incidence directe sur votre capacité à répondre aux demandes des clients.
Lien avec la notion de consolidation de profils / « single customer view »
On parle souvent de consolidation de profils, ou « single customer view », pour désigner cette vue unifiée des clients obtenue grâce à la résolution d’identité. Consolider les informations de la base client autour d’un identifiant unique est en effet le moyen le plus efficace d’obtenir un référentiel centralisé et accessible par tous les systèmes opérationnels (CRM, marketing automation, service client…).
La résolution d’identité constitue donc la fondation essentielle pour construire des profils clients riches et fiables, à même d’alimenter tous les cas d’usage du marketing personnalisé et du CRM.
Les différentes approches de résolution d’identité : déterministe, probabiliste et hybride
Pour réconcilier les identités et construire une vue unifiée du client, deux grandes approches complémentaires existent : l’approche déterministe et l’approche probabiliste.
L’approche déterministe
L’approche déterministe se base sur des identifiants uniques et certifiés comme l’adresse e-mail, le numéro de téléphone ou le login pour faire le lien entre les enregistrements client.
Par exemple, si un individu utilise la même adresse e-mail pour s’inscrire à une newsletter, créer un compte sur un site e-commerce et s’identifier dans une application mobile, on peut relier ces événements de façon certaine pour reconstituer son parcours.
L’approche déterministe offre un très haut niveau de fiabilité puisqu’elle s’appuie sur des données d’identification vérifiées fournies directement par le client. C’est la méthode à privilégier pour les cas d’usage critiques comme l’authentification ou les transactions par exemple.
Mais cette approche a ses limites. D’abord, elle ne fonctionne que pour les clients qui se sont identifiés, laissant de côté une grande partie des visiteurs anonymes. Ensuite, elle part du principe qu’un identifiant = une personne, ce qui n’est pas toujours le cas. Un même individu peut utiliser plusieurs adresses e-mail, et inversement un même identifiant peut être partagé par un foyer.
L’approche probabiliste
L’approche probabiliste va plus loin en exploitant un ensemble de signaux pour déduire l’identité d’un individu de façon statistique. Plutôt que de se baser uniquement sur des identifiants explicites, elle va recouper des attributs comme :
- Les caractéristiques de l’appareil : modèle, système d’exploitation, navigateur, etc.
- Les paramètres de connexion : adresse IP, opérateur, géolocalisation, etc.
- Les données comportementales : pages visitées, produits consultés, historique d’achat, etc.
- Les informations temporelles : heures et fréquence de connexion…
En analysant les similitudes de ces signaux, des algorithmes de « machine learning » vont calculer des probabilités pour déterminer les enregistrements qui se rapportent potentiellement à un même individu.
Par exemple, si deux profils partagent la même adresse IP, le même type d’appareil, des habitudes de navigation similaires, il y a de fortes chances qu’il s’agisse de la même personne, même sans identifiant partagé.
L’intérêt est de pouvoir résoudre les identités même sans authentification, simplement à partir des traces numériques. L’approche probabiliste (on parle de « fuzzy matching » en anglais) permet d’élargir considérablement la couverture, notamment pour les visiteurs non logués.
Le revers de la médaille, c’est un taux de fiabilité plus faible, puisqu’on reste dans l’inférence statistique. Les modèles doivent donc être entraînés et optimisés en continu pour réduire la marge d’erreur.
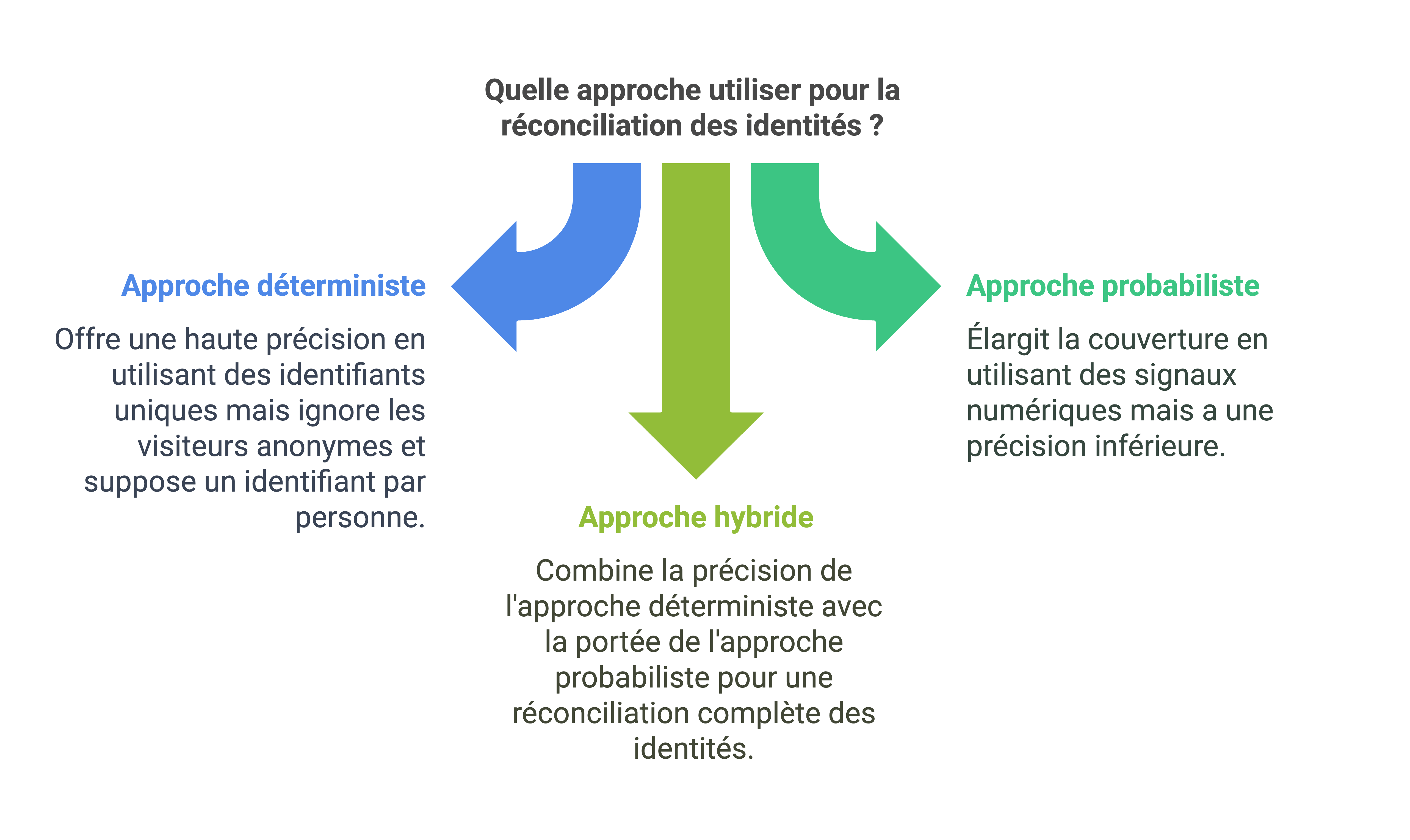
L’approche hybride
Dans la pratique, déterministe et probabiliste ne s’opposent pas mais se complètent. La tendance est d’ailleurs d’utiliser les deux en combinaison pour tirer le meilleur des deux mondes.
Un identifiant déterministe comme l’e-mail peut par exemple servir de point d’ancrage pour reconnaître un client de façon certaine, tandis que les signaux probabilistes permettront ensuite d’enrichir son profil avec ses données de navigation avant authentification.
C’est cette approche hybride qui permet d’obtenir le plus large spectre de résolution d’identité, par le croisement de données authentifiées et inférées. La clé est de définir des règles pour orchestrer ces différents niveaux de reconnaissance selon les cas d’usage : de l’identification forte lorsqu’on en a besoin, et de l’inférence pour compléter la connaissance sans friction.
Aller plus loin
si vous avez un Projet Data, ces articles sont susceptibles de vous intéresser :
Quelles données exploiter pour une résolution d’identité efficace ?
Pour obtenir une résolution d’identité performante et exhaustive, il est essentiel de s’appuyer sur un socle de données riche et varié. Voici un tour d’horizon des principales catégories de données à prendre en compte.
Les données personnelles (identité, coordonnées)
C’est la base de toute stratégie d’identification. Les données personnelles comme le nom, le prénom, l’adresse e-mail ou le numéro de téléphone permettent d’authentifier les clients de façon unique et fiable. Elles servent de clé de rapprochement pour consolider les profils à travers les différents canaux d’interaction (site web, application mobile, point de vente, service client…).
Le défi est de maintenir ces données à jour et de garantir leur qualité dans le temps, malgré les changements de coordonnées ou les doublons. D’où l’importance d’intégrer des outils de normalisation et de déduplication dans son référentiel client. Tout en veillant bien sûr à respecter les réglementations sur la collecte et l’usage des données personnelles (opt-in, gestion des consentements)…
Les données comportementales (navigation, historique d’achats…)
Pour enrichir la connaissance client, rien de tel que d’analyser les comportements en ligne et hors ligne. Historique de navigation, produits consultés ou achetés, interactions avec le service client : chaque action, chaque trace laissée par un individu est une mine d’insights pour comprendre ses attentes et personnaliser son expérience.
En recoupant ces signaux, on peut par exemple détecter qu’un client qui a acheté tel produit, consulté telle FAQ et appelé le service client rencontre probablement un problème et nécessite une attention particulière. Et ce même s’il n’était pas authentifié à chaque étape. C’est là toute la puissance du croisement déterministe / probabiliste évoqué précédemment.
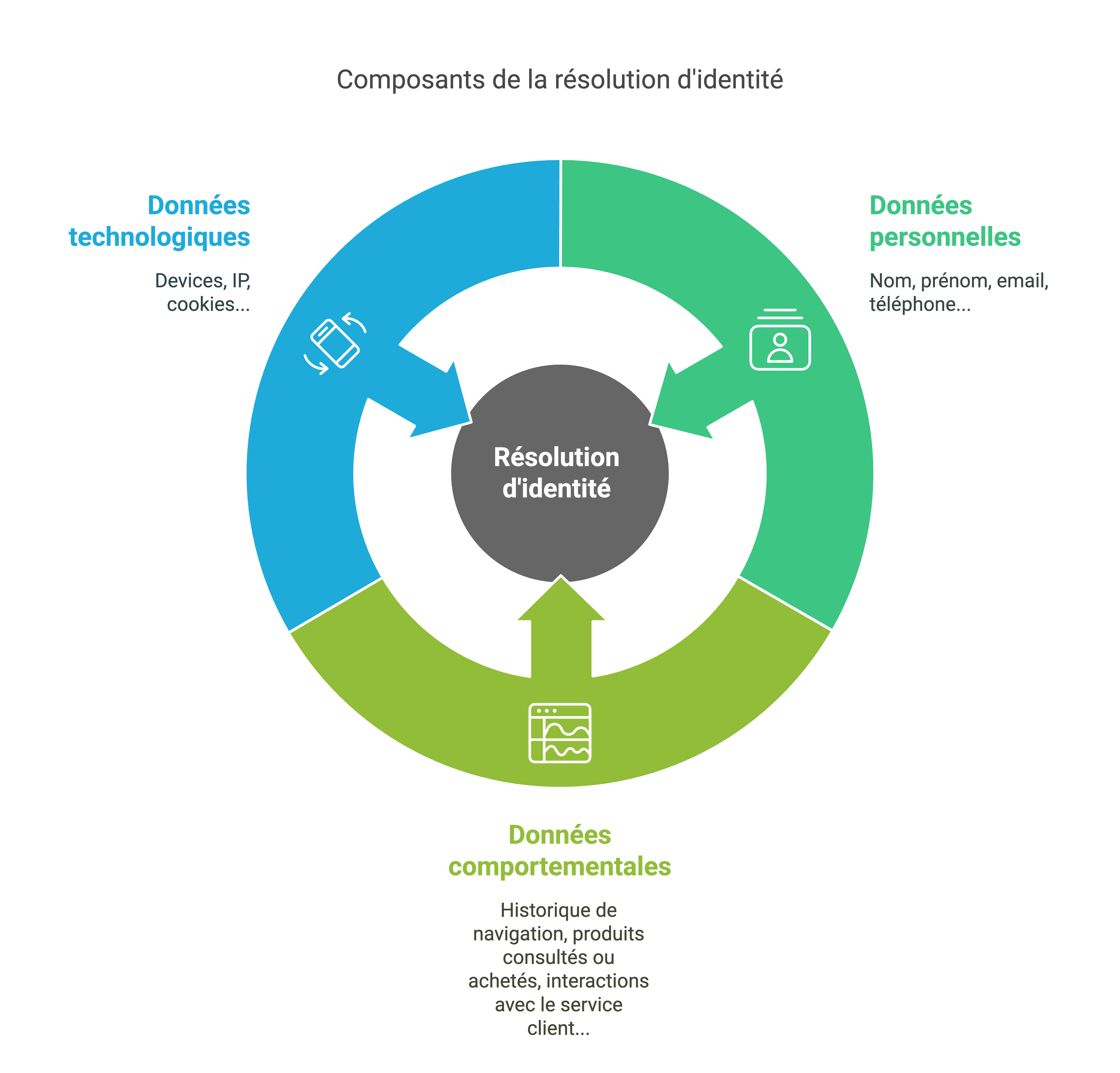
Les données technologiques (appareil, adresse IP…)
Les informations techniques issues des appareils et des connexions jouent un rôle clé dans la résolution d’identité. Elles permettent d’identifier et de relier les interactions d’un même utilisateur à travers différents terminaux.
Parmi ces données, on retrouve notamment :
- Les identifiants d’appareils (Device ID, IDFA sur mobile…)
- Les adresses IP et la géolocalisation
- Les caractéristiques du navigateur (user agent…)
- Les données issues des cookies et des tags
L’analyse croisée de ces éléments permet d’établir des correspondances entre les divers appareils utilisés par un individu (ordinateur, smartphone, tablette…).
Plus de 100 entreprises accompagnées sur leurs projets CRM et Data
Cartelis accompagne les entreprises (B2C & B2B, de la startup au grand groupe) dans le cadrage et le déploiement de Projets CRM Marketing et Data.

Comment mettre en place la résolution d’identité ?
Mener un projet de résolution d’identité peut sembler complexe au premier abord, tant les défis techniques, métiers et réglementaires sont nombreux. Chez Cartelis, nous accompagnons régulièrement des entreprises dans ce type de projet et savons que, bien mené, il apporte des bénéfices considérables.
Notre approche repose sur une méthodologie éprouvée, qui permet d’avancer avec méthode et sérénité, en priorisant les bons enjeux et en évitant les écueils courants. Nous allons vous partager ici les étapes clés que nous conseillons à nos clients pour réussir leur projet de Identity Resolution.
Etape 1 – Définir ses cas d’usage prioritaires
Avant de se lancer dans la mise en place d’une solution de résolution d’identité, il faut commencer par clarifier les objectifs du projet. La première chose à faire, c’est d’identifier les cas d’usage qui auront le plus d’impact sur votre activité. La résolution d’identité peut servir de nombreux objectifs : amélioration de l’expérience client, personnalisation des campagnes marketing, fiabilisation des analyses de données, lutte contre la fraude…Il faut éviter de se disperser et concentrer les efforts sur les cas d’usage les plus stratégiques.
Nous conseillons généralement à nos clients de se poser les questions suivantes :
- Quels sont les points de friction actuels liés à la gestion des identités clients ? Perdez-vous des ventes à cause d’un manque de reconnaissance des utilisateurs entre différents canaux ? Avez-vous des doublons dans vos bases qui faussent vos analyses ?
- Quelles équipes bénéficieront le plus de ce projet ? Est-ce un besoin prioritaire pour le marketing, la relation client, la conformité réglementaire ?
- Quels gains espérez-vous en tirer ? Réduction des coûts d’acquisition grâce à une meilleure segmentation ? Amélioration du taux de conversion grâce à des recommandations plus précises ? Renforcement de la conformité RGPD ?
En fonction des réponses, nous aidons nos clients à établir une feuille de route claire, avec des priorités bien définies et des indicateurs de succès concrets.
Retenez bien ceci : un bon projet d’Identity Resolution commence toujours par un cadrage précis, qui permet d’aligner les équipes et d’assurer un déploiement efficace et rentable.
Discutons de votre projet
Besoin d'accompagnement à la conception et au déploiement de votre projet data ?
Prenons contactEtape 2 – Cartographier ses sources de données et ses applications clientes
Il est important d’avoir une vision claire de l’écosystème de données existant. La résolution d’identité repose sur la capacité à agréger des informations issues de différentes sources et à les rendre exploitables par les équipes métiers.
La première étape consiste à identifier et hiérarchiser les sources de données qui alimenteront la résolution d’identité :
- Le logiciel CRM, qui est bien souvent le référentiel principal des interactions clients.
- Le CMS et les données web, pour capturer les comportements en ligne et les parcours utilisateurs.
- Les applications mobiles, avec des identifiants spécifiques comme les Device ID.
- Les outils transactionnels et ERP, qui centralisent l’historique des achats et des interactions financières.
- Les bases de support client et helpdesk, qui contiennent des informations précieuses sur les interactions entre l’entreprise et ses clients.
Ensuite, il est indispensable d’identifier les applications métiers qui exploiteront ces données consolidées. Une fois les profils clients unifiés, quelles équipes en auront besoin ? Il peut s’agir des outils de marketing automation, des solutions analytiques et BI, des outils de relation client, etc.
Enfin, il faut cartographier les flux de données : comment circulent actuellement les informations entre ces différentes briques ? Où se situent les silos et les redondances ? Ce travail vous aidera à identifier les zones de friction et les passerelles à construire pour assurer une circulation fluide et efficace des données.
Cet exercice est clé pour anticiper les impacts organisationnels et les ajustements de processus nécessaires. L’Identity Management n’est pas qu’un sujet technique : il doit s’intégrer dans les usages quotidiens des équipes et être adopté par l’ensemble des parties prenantes. Et une bonne cartographie permet d’aligner les besoins métiers avec les exigences techniques et de bâtir une architecture scalable et pérenne.
Etape 3 – Choisir une plateforme d’Identity Resolution
Une fois les besoins clarifiés et les flux de données cartographiés, il faut choisir la solution technique qui permettra de réaliser la résolution d’identité. De plus en plus, cette fonction est intégrée directement dans les Customer Data Platforms (CDP) ou, dans certaines architectures modernes, au sein du data warehouse.
Les CDP sont conçues pour centraliser et unifier les données clients en temps réel. Elles intègrent (en général) nativement des fonctionnalités avancées de matching, de déduplication et de gestion des consentements, et ont l’avantage de s’intégrer avec les outils marketing et CRM. Pour les entreprises cherchant une solution orientée activation marketing et personnalisation, une CDP constitue souvent le meilleur choix.
Mais la consolidation des données et la résolution d’identité peut aussi être réalisée directement dans le data warehouse. Avec l’essor des architectures modernes (les cloud data warehouses comme Snowflake, BigQuery ou Redshift), il est désormais possible de traiter ces opérations au plus près de la donnée brute, en s’appuyant sur des requêtes SQL avancées et des outils de transformation (dbt, Spark, etc.). Cette approche permet un contrôle plus fin sur les algorithmes de rapprochement et évite la multiplication des outils, mais elle demande aussi des compétences techniques solides en interne.
Quel que soit le choix technologique, plusieurs critères doivent être pris en compte pour sélectionner la bonne solution :
- La capacité à ingérer et traiter des données multi-sources (CRM, web, mobile, ERP, support client…).
- La puissance et la flexibilité des algorithmes de matching, qu’ils soient déterministes (e-mail, numéro client…) ou probabilistes (analyse comportementale, fingerprinting…).
- L’interopérabilité et la richesse des API, pour assurer une connexion fluide avec le reste de l’écosystème technologique.
- La gestion de la confidentialité et la conformité RGPD, avec une traçabilité des consentements et un contrôle des accès aux données sensibles.
- Le coût et la scalabilité, notamment la capacité à traiter de grands volumes de données sans surcoût prohibitif.
Le choix de l’outil ne doit pas être une finalité en soi. Ce qui garantit la réussite d’un projet d’Identity Resolution, c’est avant tout la qualité des données en entrée, la capacité à orchestrer efficacement les processus métiers et une gouvernance des données robuste pour assurer la pérennité du dispositif.
Etape 4 – Mettre en place les connecteurs et les règles de rapprochement
Une fois la plateforme choisie, il faut intégrer les sources de données et définir les règles de matching.
Les informations client doivent être centralisées en connectant les bases CRM, web, mobile et transactionnelles via des API, des Web Services ou des traitements batch.
On l’a vu, le rapprochement des identités repose sur :
- Le matching déterministe (correspondances exactes, e-mail, téléphone…).
- Le matching probabiliste (similarités partielles, device fingerprinting…).
Nous conseillons de démarrer avec des règles simples, puis d’affiner progressivement selon les résultats. L’objectif est de minimiser les erreurs de fusion ou de séparation des profils.
Une fois ces éléments en place, la résolution d’identité est fonctionnelle, mais son efficacité doit être continuellement mesurée et ajustée.
Etape 5 – Mesurer la performance et affiner les modèles
Le travail ne s’arrête pas à l’implémentation : la résolution d’identité doit être optimisée en continu.
Nous recommandons de monitorer régulièrement :
- Le taux de couverture des profils unifiés, qui mesure la proportion de clients pour lesquels toutes les identités ont été correctement consolidées. Un taux trop bas indique que certaines données restent isolées.
- Le taux de précision des rapprochements, qui sert à contrôler la qualité des fusions d’identités en évitant deux erreurs majeures :
- Les faux positifs (fusion incorrecte de deux profils distincts).
- Les faux négatifs (absence de fusion de plusieurs identités d’un même client).
- Le taux de doublons restants, qui représente le nombre de profils encore dupliqués dans la base, ce qui peut fausser les analyses et impacter les performances des campagnes marketing.
Ces KPIs permettent d’identifier les ajustements à apporter aux règles de matching.
Les comportements clients et les données évoluent, ce qui rend indispensable une optimisation régulière des règles. Cela passe par l’analyse des erreurs de rapprochement, l’ajustement des seuils de matching en fonction des retours terrain et des tests sur un échantillon avant déploiement global.
Vous souhaitez unifier vos données client ? Discutons-en !
Vous avez compris l’importance d’une vision client unifiée. Vous savez que sans une consolidation efficace des données, impossible d’offrir une expérience fluide, de fiabiliser vos analyses ou de garantir la conformité RGPD. Bref, vous avez fait le plus dur : prendre conscience que la résolution d’identité est un levier stratégique pour votre entreprise.
Mais entre la prise de conscience et la mise en œuvre, il y a un monde. Quels sont les bons cas d’usage à prioriser ? Comment structurer l’intégration des données ? Quelle solution choisir parmi les nombreuses options disponibles ? Et surtout, comment s’assurer que la qualité des rapprochements est au rendez-vous ?
C’est là que nous intervenons. Chez Cartelis, nous accompagnons depuis des années des entreprises dans l’unification de leurs données clients. Nous savons ce qui fonctionne, ce qui pose problème, et comment accélérer la mise en place tout en assurant des résultats durables.
Notre approche ? Une expertise à la croisée des enjeux métiers et techniques. Nous parlons aussi bien aux équipes marketing qu’aux data engineers et responsables IT. Nous traduisons vos besoins en solutions concrètes et adaptées à votre environnement, sans multiplier les couches d’outils inutiles.
Et surtout, nous avons une conviction : vous donner les clés pour être autonomes. Notre mission ne s’arrête pas à la mise en place technique. Nous vous aidons à structurer une gouvernance des données efficace et à développer les compétences internes nécessaires pour que votre dispositif de résolution d’identité soit performant sur le long terme.
Vous souhaitez unifier vos données ? Parlons-en !